Cela faisait un moment que je voulais à nouveau m’essayer à construire un tableau du type Excel ou Google Sheets me permettant, à l’aide de l’intelligence artificielle, de générer des appréciations, non pas pour écrire des bulletins à ma place, mais pour m’assister dans la tâche d’analyse de données toujours plus nombreuses.
Voici comment ça s’est passé et de quelle façon je m’y suis pris.
En lisant le Times
Dimanche dernier, je lisais dans le Times un article intitulé AI could help save the NHS — but not in the ways you may think. On pouvait y lire que les médecins passent un temps considérable à rédiger de la paperasse administrative et à mettre en forme les notes qu’ils prennent après une consultation pour le suivi de leurs patients.
Dom Pimenta, a 36-year-old cardiologist and the founder of Tortus, said: “If you look at the maths, up to 60 per cent of the time is spent with computers, which means 40 per cent of the time is spent with patients.
“If you get that computer time down to 15 per cent, you are getting 85 per cent of the time with patients. Imagine what the NHS could do with that many more doctors or nurses.” 1
L’IA pourrait donc aider les médecins à réduire ce temps qu’ils pourraient ainsi consacrer à leurs patients plutôt que de s’asseoir devant leur ordinateur.
Je ne suis pas allé explorer ce que propose Tortus (« Doctors, not data clerks », ai-je pu toutefois entrapercevoir), mais je comprends à la lecture de l’article qu’il s’agit d’une IA qui pourrait « écouter » durant la consultation et rédiger automatiquement une synthèse, ce qui ne va pas sans poser différents problèmes en termes de vie privée, mais passons.
L’être humain et la machine
Je trouve cela très intéressant parce que l’article fait valoir que l’adoption de l’IA sera lente à pénétrer le domaine médical pour de nombreuses raisons, mais aussi parce que de toutes les merveilles que notre technologie peut produire, celle qui a le plus de chance d’être rapidement adoptée est cette modeste tâche de suppléer l’être humain dans ses fonctions administratives et non de le remplacer. En somme, les brillantes technologies que des Oppenheimmer repentis nous annoncent comme susceptibles de mettre fin à l’humanité sont en train de rentrer par la petite porte de la prose administrative plutôt que celle du grand remplacement par des IA aux commandes de scanners automatisés. Intéressant, non ? In fine, c’est la même histoire depuis Kasparov et qui, dans les réflexions subséquentes du champion, a donné naissance à l’image du centaure et que l’auteur de Co-Intelligence semble reprendre à son compte sous une autre appellation.
Mais je me suis dit que, de fait, il en allait de même avec les enseignants. Comment faire pour qu’ils passent plus de temps avec leurs élèves plutôt que d’écrire des mails ou des bulletins ? Comment leur permettre d’accélérer toutes les tâches qui les rapprochent de leur ordinateur et les éloignent de leurs élèves ? On peut acheter, s’abonner, télécharger un tas de trucs, mais n’est-ce pas un peu dommage ? Ne peut-on profiter de cette brillante technologie pour bâtir soi-même ses propres outils ? Je me suis alors rappelé qu’il y avait quelque chose à faire même si mes compétences en matière de code sont désastreuses. Après tout, ne suffit-il pas de demander à chatGPT ? C’est ce que j’ai fait (la conversation peut être consultée en cliquant sur ce lien).
Un tableur pour aider dans la rédaction des appréciations
Pour mon premier essai, j’ai demandé à chatGPT d’écrire un script pour Google Sheets permettant d’utiliser l’API d’OpenAI. Compte tenu du faible coût que cela représente, on pourrait imaginer investir dans ce genre de choses plutôt que des abonnements à 20 euros le mois. Comme on peut le voir ci-dessous, le coût du token (pour GPT 4) est de $0.003.
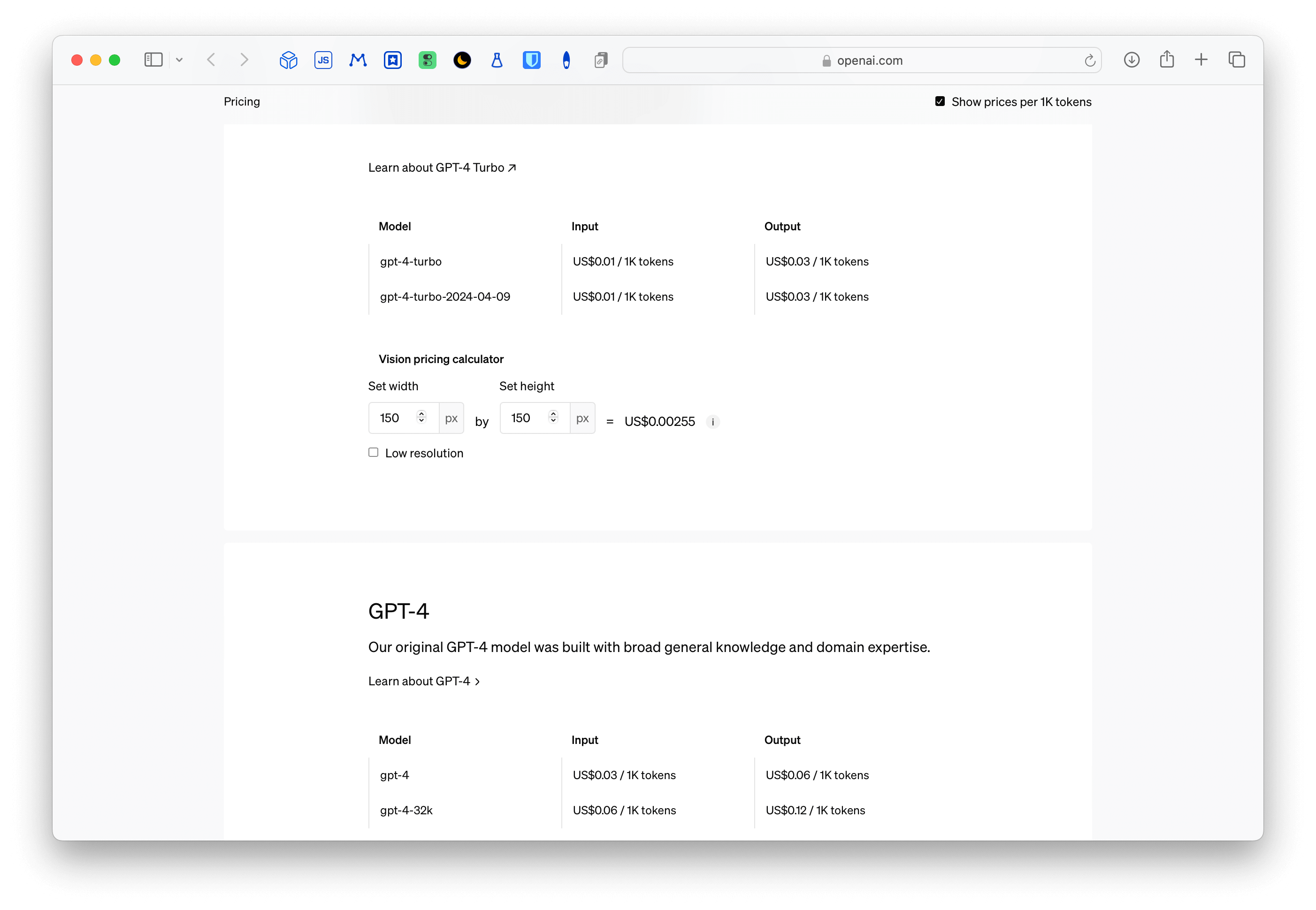
Bref, assez rapidement, j’ai eu mon script que voici (après quelques essais/erreurs).
const OPENAI_API_KEY = 'Insérer votre clé';
const OPENAI_API_URL = 'https://api.openai.com/v1/chat/completions';
/**
* Submits a prompt to GPT and returns the completion
*
* @param {string} prompt Prompt to submit to GPT
* @param {float} temperature Model temperature (0-1)
* @param {string} model Model name (e.g., gpt-4)
* @param {int} maxTokens Max Tokens (< 4000)
* @return Completion from GPT
* @customfunction
*/
function GPT(prompt, temperature = 0.6, model = 'gpt-4', maxTokens = 256) {
var data = {
model: model,
messages: [{"role": "user", "content": prompt}],
temperature: temperature,
max_tokens: maxTokens
};
var options = {
method: 'post',
contentType: 'application/json',
payload: JSON.stringify(data),
headers: {
'Authorization': `Bearer ${OPENAI_API_KEY}`,
'Content-Type': 'application/json'
}
};
var response = UrlFetchApp.fetch(OPENAI_API_URL, options);
var responseData = JSON.parse(response.getContentText());
if (responseData.choices && responseData.choices.length > 0) {
return responseData.choices[0].message.content.trim();
} else {
return 'No response from OpenAI API';
}
}
/**
* Submits examples to GPT and returns the completion
*
* @param {Array<Array<string>>} examples_input Range of cells with input examples
* @param {Array<Array<string>>} examples_output Range of cells with output examples
* @param {string} input Cell to pass as input for completion
* @param {float} temperature Model temperature (0-1)
* @param {string} model Model name (e.g., gpt-4)
* @param {int} maxTokens Max Tokens (< 4000)
* @return Completion from GPT
* @customfunction
*/
function GPT_RANGE(examples_input, examples_output, input, temperature = 0.6, model = 'gpt-4', maxTokens = 256) {
let prompt = `I am an input/output bot. Given example inputs, I identify the pattern and produce the associated outputs.`;
for (let i = 0; i < examples_input.length; i++) {
let example_input = examples_input[i][0];
let example_output = examples_output[i][0];
prompt += `\n\nInput: ${example_input}\nOutput: ${example_output}`;
}
prompt += `\n\nInput: ${input}\nOutput:`;
return GPT(prompt, temperature, model, maxTokens);
}
Pour résumer, tout ce que vous avez à faire est de
- créer un compte sur OpenAI, acheter quelques crédits et obtenir une clé API
- créer un Google Sheets
- aller dans
Extensions>Apps Script - coller le code ci-dessus en incluant votre clé API
Vous pouvez aussi télécharger ce modèle, mais n’oubliez pas d’insérer votre clé.
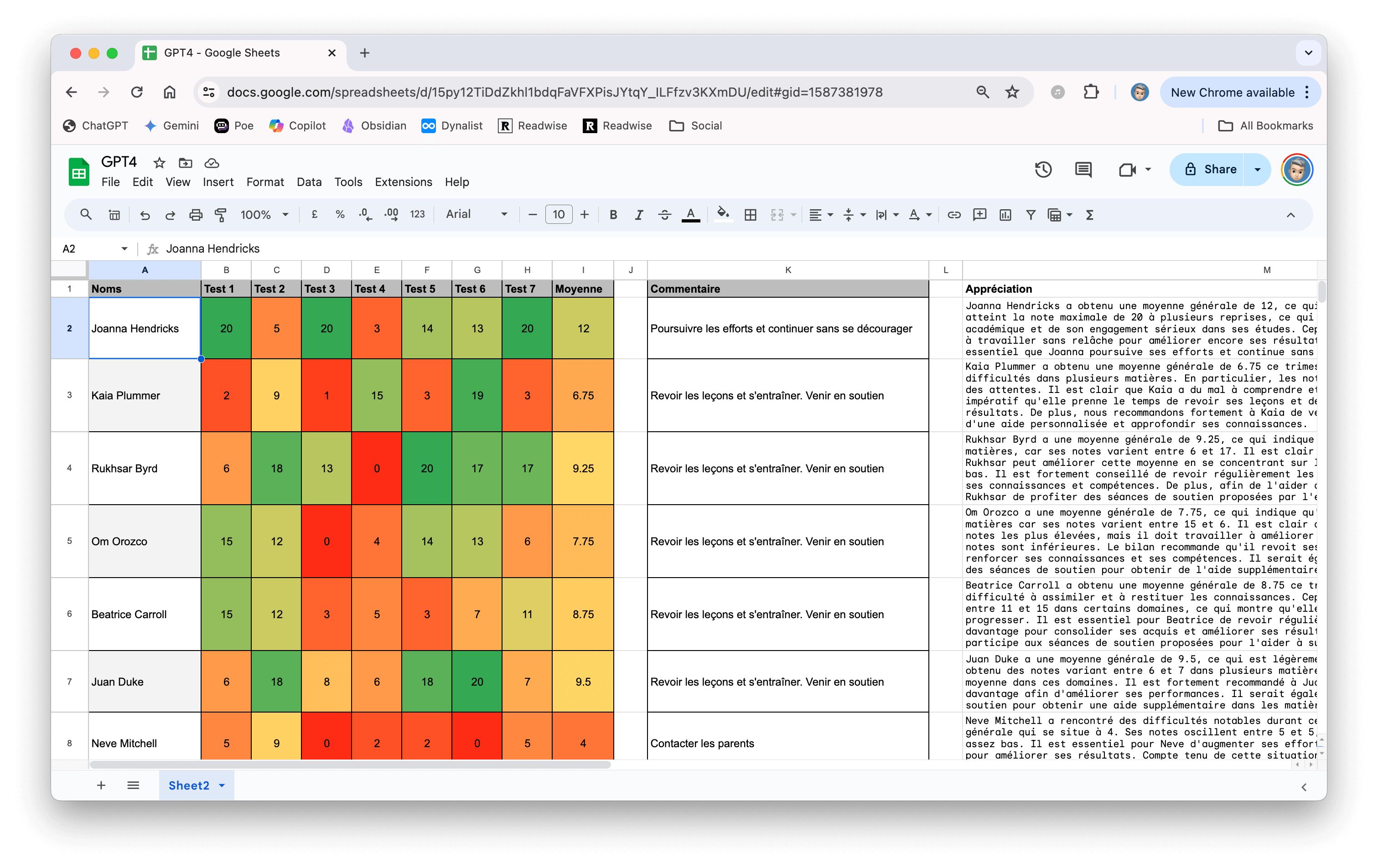
Sur ce modèle, comme vous pouvez le voir sur la capture d’écran ci-dessus, j’ai indiqué plusieurs choses.
Tout d’abord, il y a le noms des élèves (de faux noms évidemment).
Ensuite, il y a des notes (fausses également, générées aléatoirement avec la fonction RANDBETWEEN).
=RANDBETWEEN("0", "20")
Il y a la moyenne des notes (facile).
=AVERAGE(B2:E2)
Un peu de logique maintenant avec une bonne série de IF (histoire d’aider l’IA si besoin) :
=IF(I2 >= 16, "Félicitations!",
IF(AND(I2 <= 15, I2 > 13), "Bon travail !",
IF(AND(I2 <= 12, I2 > 10), "Poursuivre les efforts et continuer sans se décourager",
IF(AND(I2 < 10, I2 > 5), "Revoir les leçons et s'entraîner. Venir en soutien",
"Contacter les parents"
)
)
)
)
Et enfin, notre GPT (c’est en fait le prompt qui marche uniquement parce que nous avons inséré le script ci-dessus).
=GPT("Écris le bulletin de cet élève en 4 ou 6 phrases pour '"&A2&"'. Prends en considération la moyenne des notes se trouvant en '"&I2&"' ainsi que les notes se trouvant de '"&B2&"' à '"&H2&"' ainsi que le bilan en '"&K2&"'")
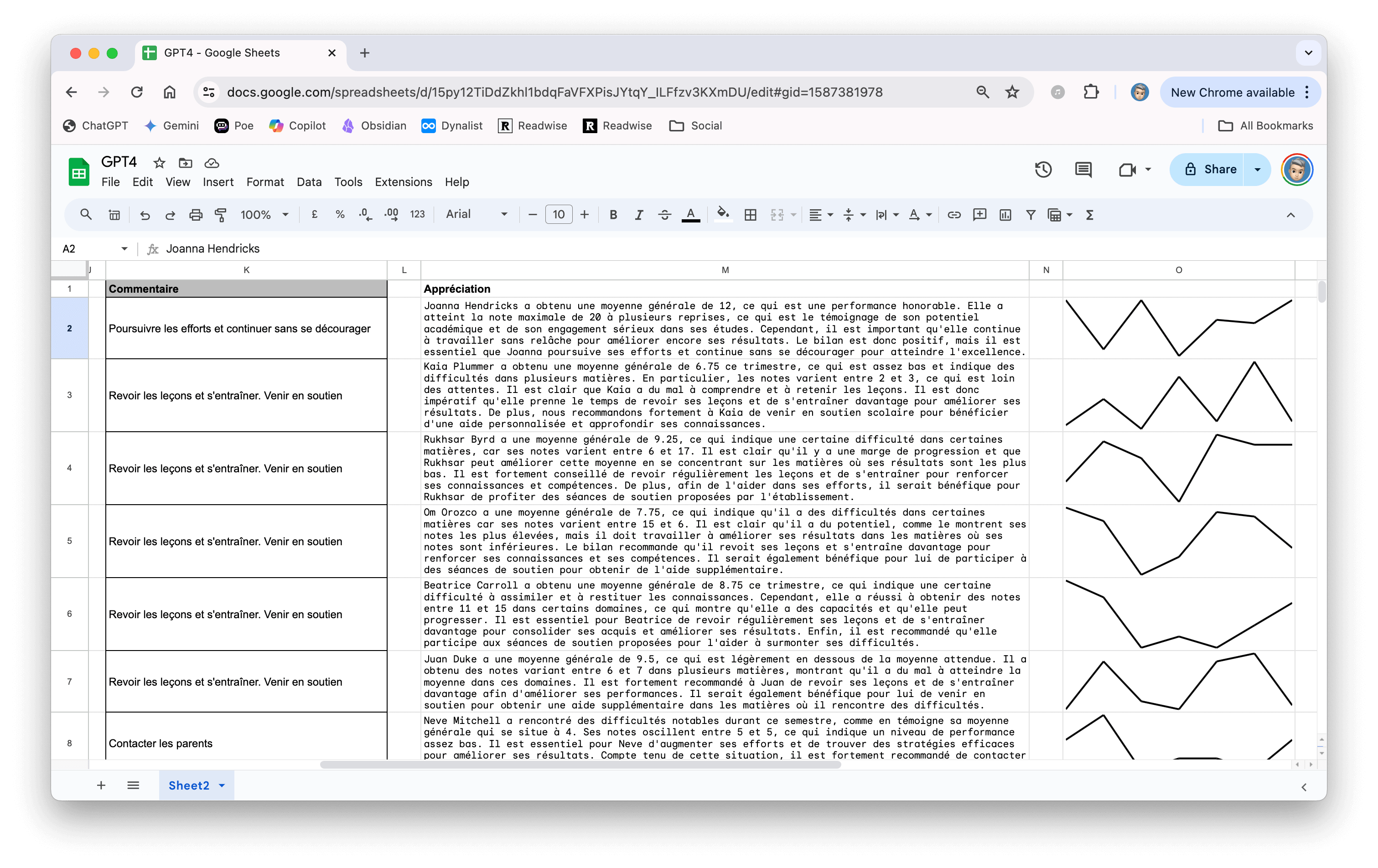
Vous remarquerez que je me suis aussi amusé à insérer un petit graphique qui indique la progression.
=SPARKLINE(B2:H2, {"linewidth", 2})
Et enfin vous voudrez bien vous rappeler que notre stochastic parrot n’a pas pour fonction de vous remplacer ni d’écrire les bulletins à notre place, mais de générer (en plusieurs versions si nécessaire) des conseils et analyser des résultats qu’il vous revient de relire, corriger, compléter et assumer puisqu’en dernière instance, vous restez l’auteur et que c’est votre responsabilité qui est engagée. Enfin (encore), on gardera à l’esprit que l’IA est très, très forte pour produire le même verbiage creux dont nous avions auparavant la gênante exclusivité et qui est donc maintenant capable, comme un enseignant qui au comble de l’ennui et qui aurait déjà rempli 237 bulletins, d’écrire des banalités du type « Doit se mettre au travail blablabla ».
Je dis souvent à qui veut l’entendre quand on m’interroge sur le sujet qu’il faut considérer que l’IA vous assiste, mais ne se substitue pas à vous. Elle le fait à la manière d’un assistant plein de bonne volonté, un jeune assistant, probablement un stagiaire pour lequel il faut tout, mais alors absolument tout relire.
Mais je me suis dit qu’on pouvait continuer longtemps comme ça et j’ai encore demandé des choses à chatGPT.
Votre traitement de texte est votre assistant
Cette fois, l’idée est d’avoir GPT dans Google Docs. Ce n’est pas très original. Gemini rôde déjà par là. Des extensions proposent déjà ce genre de choses, mais en procédant ainsi (c’est-à-dire en faisant les choses soi-même), on l’a dit, c’est très, très peu cher. Une requête est de l’ordre de $0.009 et des brouettes. Et on peut se construire son petit bot selon ses propres besoins (laissez-moi un peu de temps, et je peaufinerai tout cela).
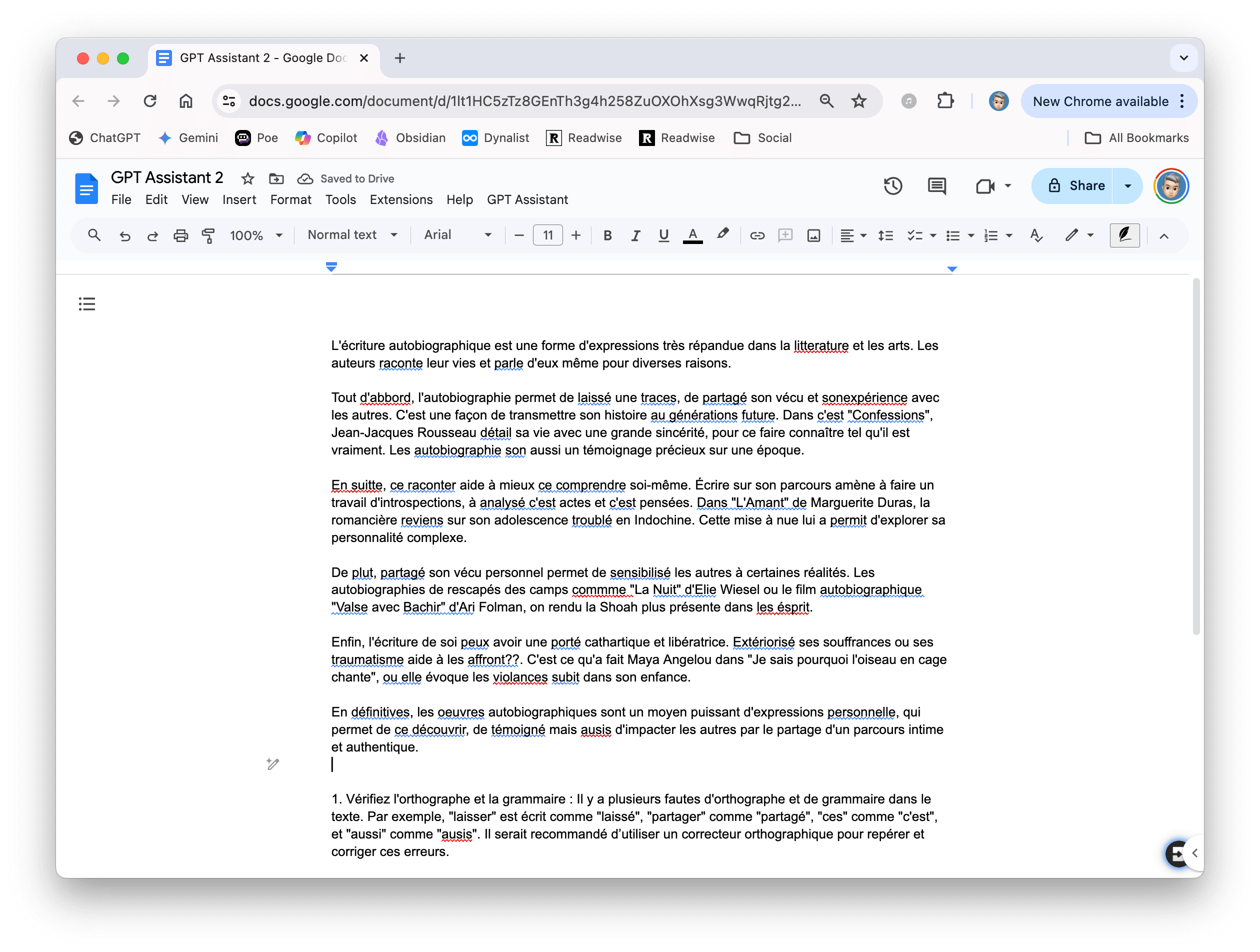
J’en ai fait plusieurs versions. Dans la deuxième, j’ai demandé que GPT soit capable de lire le contenu du document. Voici le script.
const OPENAI_API_KEY = ''; // <- PASTE YOUR SECRET KEY HERE
const OPENAI_API_URL = 'https://api.openai.com/v1/chat/completions';
/**
* Fetch completion from OpenAI API
*
* @param {string} prompt The input prompt for GPT-4
* @param {string} content The content of the Google Docs
* @param {string} model The model to use (e.g., gpt-4)
* @param {float} temperature The sampling temperature (0-1)
* @param {int} maxTokens The maximum number of tokens to generate
* @return {string} The generated completion
*/
function fetchCompletion(prompt, content, model = 'gpt-4', temperature = 0.6, maxTokens = 256) {
var data = {
model: model,
messages: [
{"role": "system", "content": "You are an assistant that helps improve and process text."},
{"role": "user", "content": content},
{"role": "user", "content": prompt}
],
temperature: temperature,
max_tokens: maxTokens
};
var options = {
method: 'post',
contentType: 'application/json',
payload: JSON.stringify(data),
headers: {
'Authorization': `Bearer ${OPENAI_API_KEY}`,
'Content-Type': 'application/json'
}
};
var response = UrlFetchApp.fetch(OPENAI_API_URL, options);
var responseData = JSON.parse(response.getContentText());
if (responseData.choices && responseData.choices.length > 0) {
return responseData.choices[0].message.content.trim();
} else {
return 'No response from OpenAI API';
}
}
/**
* Process the content of the Google Doc with OpenAI API
*/
function processContent() {
var doc = DocumentApp.getActiveDocument();
var body = doc.getBody();
var content = body.getText();
var prompt = DocumentApp.getUi().prompt('Enter your prompt for GPT-4').getResponseText();
var processedContent = fetchCompletion(prompt, content);
body.appendParagraph('\nProcessed Content:\n');
body.appendParagraph(processedContent);
}
/**
* Create a custom menu in the Google Docs UI
*/
function onOpen() {
DocumentApp.getUi().createMenu('GPT Assistant')
.addItem('Process Content', 'processContent')
.addToUi();
}
Voici le prompt que j’ai utilisé pour corriger une rédaction (générée par Claude qui, avec complaisance, a ajouté pas mal d’erreurs d’orthographe que chatGPT n’a qu’une envie, c’est de corriger) :
Propose des conseils de correction sur ce texte écrit par une élève de collège (troisième dans le système français). Ne corrige pas le texte, propose juste quelques conseils pour que l’élève améliore son travail.
Évidemment, si la chose vous dit, vous pouvez demander à chatGPT de créer un add-on pour vous. C’est plus riche et plus complet. Plus interactif aussi. Bref, assez rigolo. Il y a juste une étape supplémentaire qui consiste à créer un fichier HTML.
<!DOCTYPE html>
<html>
<head>
<base target="_top">
</head>
<body>
<h2>GPT Assistant</h2>
<div>
<label for="prompt">Enter your prompt:</label><br>
<textarea id="prompt" rows="4" cols="50"></textarea><br><br>
<button onclick="processDoc()">Process Document</button>
</div>
<script>
function processDoc() {
const prompt = document.getElementById('prompt').value;
google.script.run.processContent(prompt);
document.getElementById('prompt').value = '';
}
</script>
</body>
</html>
Et évidemment le script.
const OPENAI_API_KEY = ''; // <- PASTE YOUR SECRET KEY HERE
const OPENAI_API_URL = 'https://api.openai.com/v1/chat/completions';
/**
* Fetch completion from OpenAI API
*
* @param {string} prompt The input prompt for GPT-4
* @param {string} content The content of the Google Docs
* @param {string} model The model to use (e.g., gpt-4)
* @param {float} temperature The sampling temperature (0-1)
* @param {int} maxTokens The maximum number of tokens to generate
* @return {string} The generated completion
*/
function fetchCompletion(prompt, content, model = 'gpt-4', temperature = 0.6, maxTokens = 256) {
var data = {
model: model,
messages: [
{"role": "system", "content": "You are an assistant that helps improve and process text."},
{"role": "user", "content": content},
{"role": "user", "content": prompt}
],
temperature: temperature,
max_tokens: maxTokens
};
var options = {
method: 'post',
contentType: 'application/json',
payload: JSON.stringify(data),
headers: {
'Authorization': `Bearer ${OPENAI_API_KEY}`,
'Content-Type': 'application/json'
}
};
var response = UrlFetchApp.fetch(OPENAI_API_URL, options);
var responseData = JSON.parse(response.getContentText());
if (responseData.choices && responseData.choices.length > 0) {
return responseData.choices[0].message.content.trim();
} else {
return 'No response from OpenAI API';
}
}
/**
* Process the content of the Google Doc with OpenAI API
*/
function processContent(prompt) {
var doc = DocumentApp.getActiveDocument();
var body = doc.getBody();
var content = body.getText();
var processedContent = fetchCompletion(prompt, content);
body.appendParagraph('\nProcessed Content:\n');
body.appendParagraph(processedContent);
}
/**
* Show the sidebar for user input
*/
function showSidebar() {
var html = HtmlService.createHtmlOutputFromFile('Sidebar')
.setTitle('GPT Assistant')
.setWidth(300);
DocumentApp.getUi().showSidebar(html);
}
/**
* Create a custom menu in the Google Docs UI
*/
function onOpen() {
DocumentApp.getUi().createMenu('GPT Assistant')
.addItem('Open GPT Assistant', 'showSidebar')
.addToUi();
}
Vous pouvez télécharger le modèle si cela vous intéresse. N’oubliez pas que Google vous prévient 20 fois qu’il y a un script attaché et qu’il convient d’être prudent.
Je ne les inclus pas dans ce billet de blog, mais je continue mes essais. chatGPT est en train de construire pour moi une extension pour Gmail et je fais aussi joujou avec l’API de Claude dans le même temps (pour comparer). Au reste, j’apporterai quelques améliorations à ces documents notamment au tableur permettant de générer des appréciations, car on peut faire encore bien mieux.
Je vous tiens au courant.
P.S.
On peut depuis peu connecter son compte Google ou Microsoft à chatGPT et donc demander au bot d’analyser notre tableau. Je dois dire que c’est assez impressionnant (mais plus cher que notre solution). À suivre.
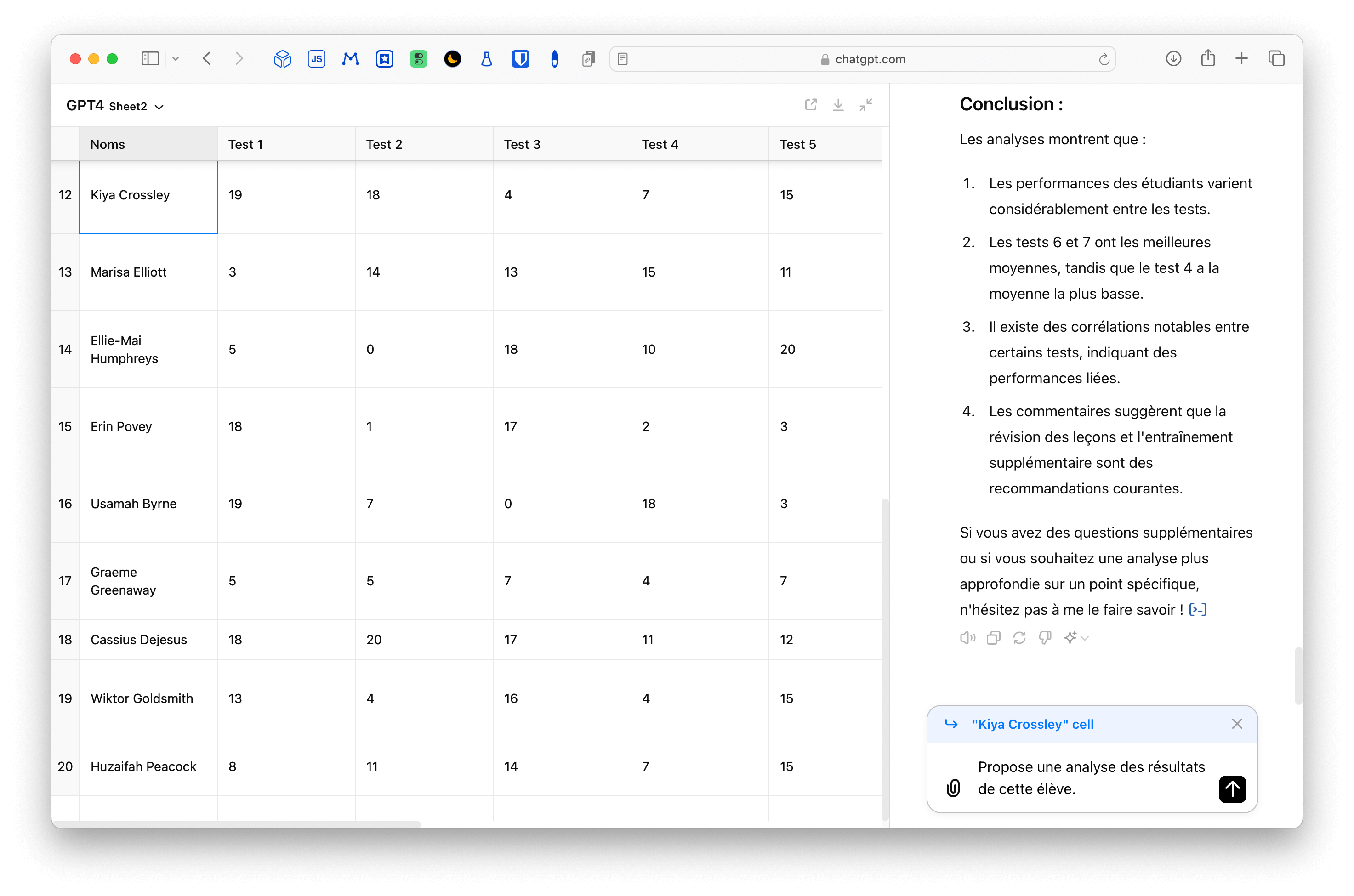
Mise à jour du 31/05/2024
Poursuivant mes expérimentations avec l’API d’OpenAI et Google Sheets, j’ai tenté deux choses, certes imparfaites, mais que je crois sinon intéressantes du moins amusantes.
La première, comme on peut le voir dans la vidéo ci-dessus, invite à choisir dans un menu déroulant des appréciations sommaires sur le comportement, les apprentissages, la progression, etc. S’appuyant sur ces brèves observations, GPT produit un commentaire grâce à la même formule (mais je me suis senti obligé de lui faire comprendre qu’il devait se comporter comme un enseignant) :
=GPT("Agis comme un enseignant et écris une appréciation pour cet élève en 4 ou 6 phrases pour '"&A4&"'. Prends en considération les observations se trouvant de '"&B4&"' à '"&H4&"' pour produire cette appréciation.")Mais comme ces appréciations valent ce qu’elles valent, j’ai eu une deuxième idée. Demandons à l’IA de produire trois versions de ce commentaire initial. J’ai donc créé un deuxième onglet récupérant l’appréciation avec cette fonction :
=IFERROR(VLOOKUP(A4, 'Appréciations 1'!$A$2:$I$21, 9, FALSE)," ")Et j’invite alors GPT à produire trois versions de ce commentaire.
Version 1 Soutenir et encourager
=GPT("Agis comme un sympathique enseignant passionné et reformule l'appréciation en '"&B3&"' de manière à soutenir et à booster l'ego de l'élève.")Version 2 Sévère et exigeante
=GPT("Agis comme un enseignant et reformule, sans la contredire mais en variant simplement le point de vue sur le travail fourni, l'appréciation en '"&B3&"' en étant plus sévère et exigeant.")Version 3 Neutre et factuel
=GPT("Agis comme un enseignant objectif et reformule l'appréciation en '"&B3&"' en étant le plus factuel possible.")Vous pouvez télécharger le tableur en cliquant sur ce lien.
1 : « Dom Pimenta, cardiologue de 36 ans et fondateur de Tortus, a déclaré : « Si l’on fait le calcul, on constate que jusqu’à 60% du temps est consacré aux ordinateurs, ce qui signifie que 40% du temps est consacré aux patients. Si l’on réduit ce temps d’utilisation de l’ordinateur à 15%, on obtient 85% du temps passé avec les patients. Imaginez ce que la NHS pourrait faire avec autant de médecins ou d’infirmières en plus. »