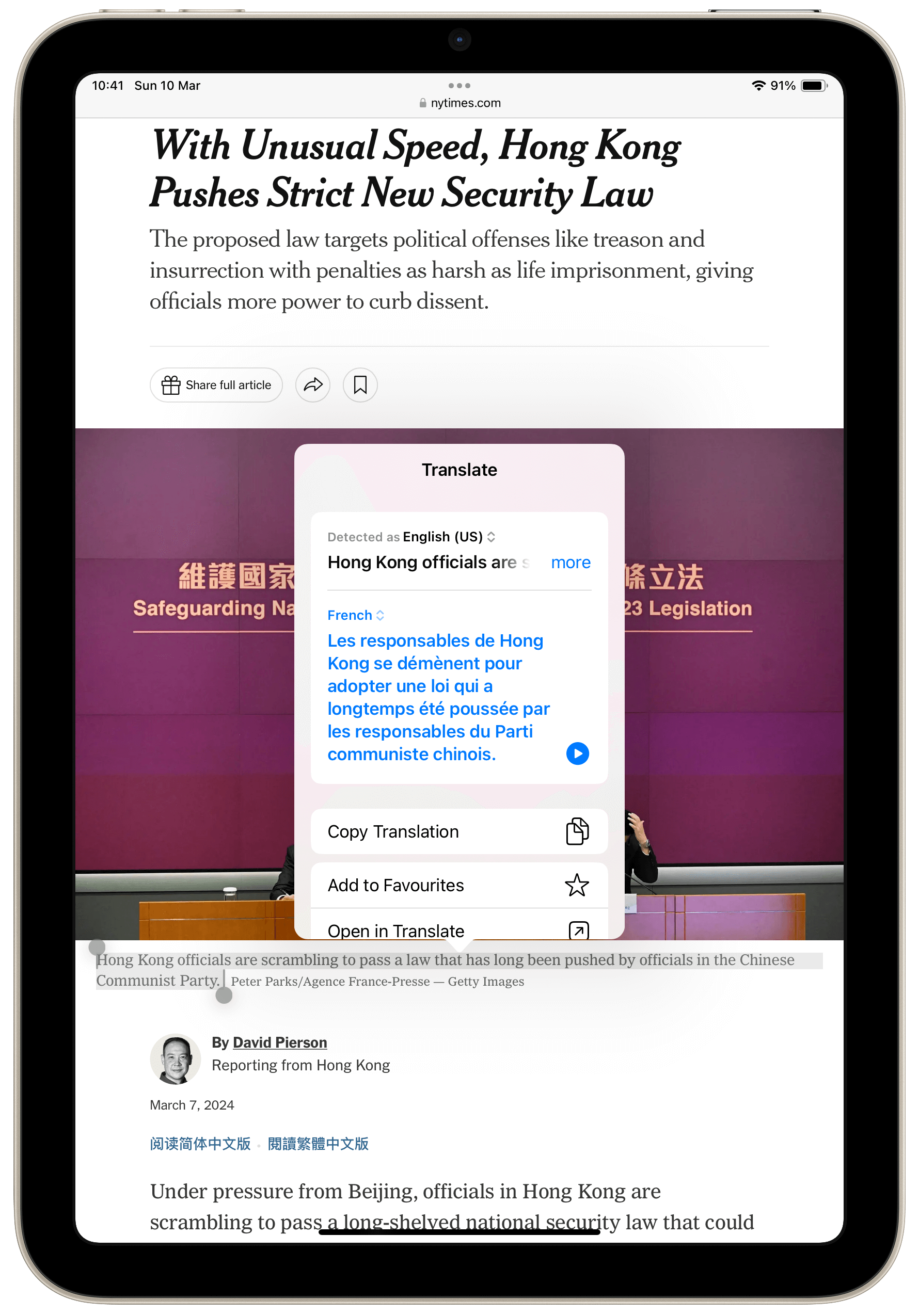
L’idée est la suivante (et je me demande pourquoi je ne l’ai pas eue avant) : je voulais que chatGPT m’aide à créer une macro pour Word.
Et cette idée est toujours la même que je décline encore et encore (voir par exemple L’IA pour aider, non pour remplace) : comment utiliser l’IA soit pour faire des choses que je sais faire, mais plus rapidement ? Ou encore : comment faire faire à l’IA des choses que je ne sais pas faire ou pas bien faire et qui font de celui qui passe commande une sorte de « power user » ?
Parce que oui, on peut utiliser ceci ou cela (par exemple, dans le cas qui nous préoccupe, le ruban du cartable fantastique), mais ici, on fait les choses soi-même ou – parce qu’il y a contradiction — on voit comment l’IA nous assiste dans le processus de création de fonctions taillées sur mesure.
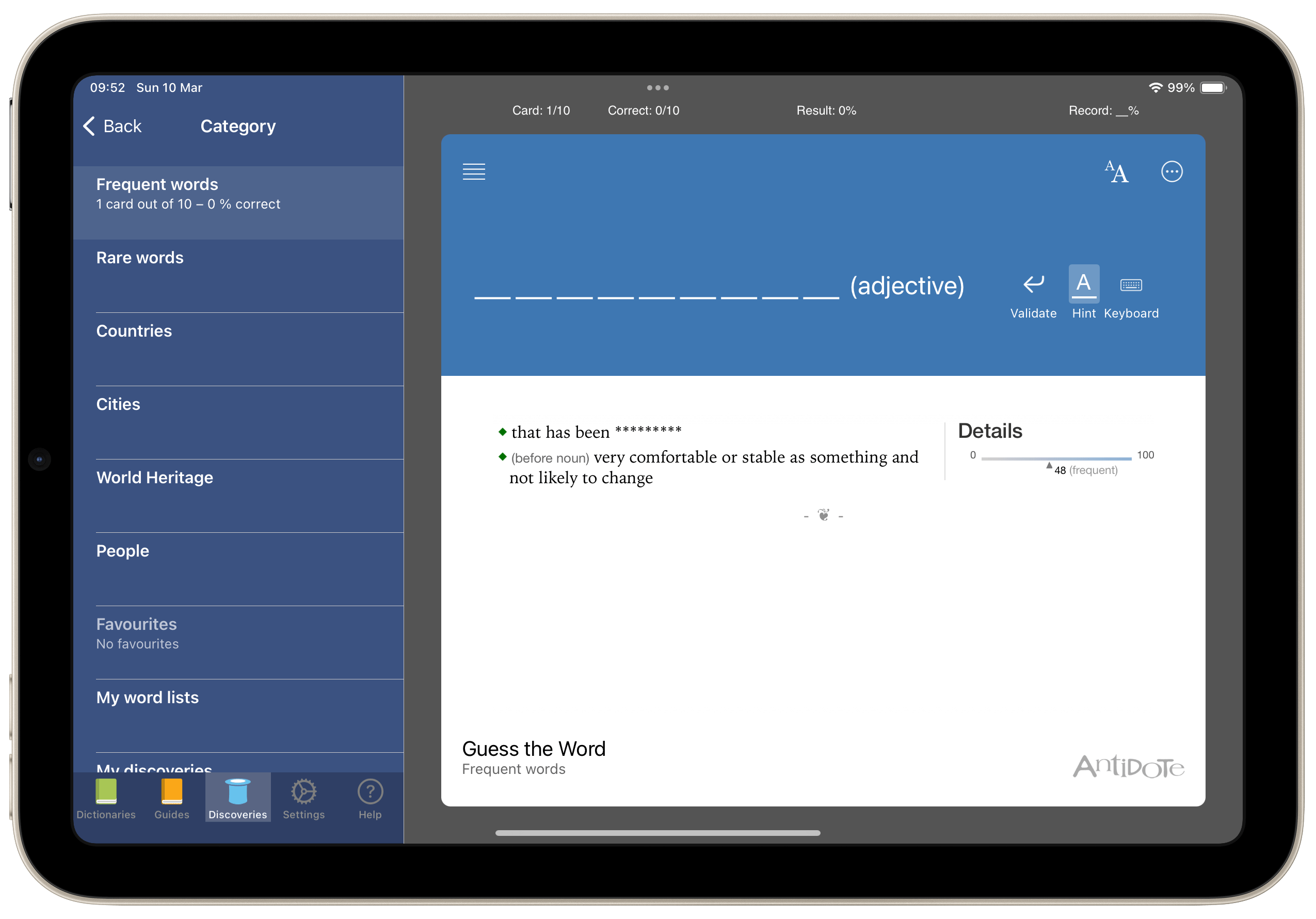
Enfin, bref, je voulais qu’en un clic, on puisse passer d’un texte quasi illisible pour un élève dyslexique en un texte dûment formaté, c’est-à-dire avec
Une police sans serif
Une taille de 14px
Un interligne de 1.5
Un espacement entre les caractères de 0.5
etc.
La macro fait tout ça en un clic. Mieux encore, elle aide l’enseignant qui ignorerait tout des subtilités éditoriales à rendre son document dyslexic friendly. Voici donc la macro, pour ceux que ça intéresse, et si vous n’avez jamais utilisé ou créé de macros, rappelez-vous, chatGPT sera très heureux de vous aider.
Sub FormatForDyslexia_WithFootnotes()
Dim para As Paragraph
Dim doc As Document
Dim style As Style
Dim footnote As Footnote
' Associer le document actif
Set doc = ActiveDocument
' Modifier le texte principal
For Each para In doc.Paragraphs
If Not para.Range.InlineShapes.Count > 0 Then
para.Range.Font.Name = "Arial"
para.Range.Font.Size = 14
para.LineSpacingRule = wdLineSpaceExactly
para.LineSpacing = 2 * 12 ' Interligne de 2
para.Alignment = wdAlignParagraphLeft
para.SpaceBefore = 6 ' Espacement avant
para.SpaceAfter = 6 ' Espacement après
para.Range.Font.Spacing = 0.5 ' Espacement des lettres
End If
Next para
' Modifier les titres
For Each style In doc.Styles
If style.Type = wdStyleTypeParagraph Then
If style.NameLocal = "Titre 1" Then
style.Font.Size = 24 ' Taille du titre 1
ElseIf style.NameLocal = "Titre 2" Then
style.Font.Size = 20 ' Taille du titre 2
ElseIf style.NameLocal = "Titre 3" Then
style.Font.Size = 18 ' Taille du titre 3
End If
End If
Next style
' Modifier les notes de bas de page
For Each footnote In doc.Footnotes
With footnote.Range
.Font.Name = "Arial"
.Font.Size = 12 ' Taille légèrement plus petite que le texte principal
.ParagraphFormat.LineSpacingRule = wdLineSpaceExactly
.ParagraphFormat.LineSpacing = 1.5 * 12 ' Interligne de 1,5
.ParagraphFormat.Alignment = wdAlignParagraphLeft
.ParagraphFormat.SpaceBefore = 3 ' Espacement avant chaque note
.ParagraphFormat.SpaceAfter = 3 ' Espacement après chaque note
End With
Next footnote
' Afficher un message de confirmation
MsgBox "Le texte et les notes de bas de page ont été formatés.", vbInformation, "Formatage terminé"
End Sub
Il fut un temps où l’idée de posséder un bureau était devenue incongrue. C’était une époque dominée par la nécessité de la mobilité, un temps où l’iPad permettait un travail s’affranchissant justement des contraintes de l’immobilité et où une jeunesse déjà menacée laissait encore mon corps s’avachir et saisir n’importe quelle opportunité de labeur, que ce soit à la table du salon, à la terrasse d’un café ou vautré sur le canapé, imprimant à ma colonne vertébrale des torsions invraisemblables.
Je ne sais pas trop ce qu’il s’est passé. Certainement, j’ai vieilli. Probablement, la pandémie est passée par là aussi. L’iPad a vu ses promesses s’étioler et, entre temps, j’ai redécouvert le Mac. Mes besoins ont évolué aussi. En témoignent les heures de visioconférence et les enregistrements de podcasts. Je crois qu’il existe aussi une mode instagramo-youtubesque des bureaux à laquelle je suis manifestement en train de céder. On y voit des environnements de travail cosy. La lumière y est tamisée. Ce sont des lieux savamment composés, patiemment organisés, délicatement mis en scène. Encore que la chose n’est pas nouvelle. Je me souviens, vingt ans en arrière, que l’on pouvait poster ses photos sur le site MacBidouille, et que je les regardais déjà avec gourmandise. Ici, nul voyeurisme mais un impérieux désir de savoir comment s’organise physiquement l’espace de travail d’autrui, quels sont les lieux de la fabrique du savoir (oui, je m’imagine un peu benoitement qu’un bureau sert en général à travailler et pas uniquement à faire des likes sur Instagram).
Enfin, bref, un jour, la nécessité d’un bureau a retrouvé toute la vigueur qu’elle avait un temps perdue. Cette idée de posséder un lieu à soi, ce petit monde que l’on peut aménager et contrôler à loisir – foin des vicissitudes du monde extérieur – n’est sûrement pas non plus étrangère à ce désir de bureau. Il faut dire que ces dix dernières années, j’ai déménagé cinq fois, et que l’envie de jeter une encre dans le confort de quelques mètres carrés est un plaisir que je ne saurais refuser.
Que trouve-t-on dans ce petit monde étalé sur une planche Ikea (en aussi en partie sur ce support dont l’esthétique correspond complètement)?
La pièce centrale est probablement le MacBook Pro M3 Max pour lequel je suis allé jusqu’à 64Go de RAM. Il est posé sur un petit support permettant de le surélever, le Twelve South HiRise Pro, et il est relié à un écran Dell (S2722QC) que je trouve plutôt pas mal pour un prix relativement correct. J’aurais bien pris plus grand, mais on atteint vite des sommes faramineuses, surtout si on veut monter en résolution (5K). Sur cet écran, vous trouverez (je ne sais pas trop comment nommer cela en français) une barre d’écran BenQ qui, outre qu’elle offre une source de lumière supplémentaire (deux en fait), atténue un peu l’éclat de la luminosité de l’écran le soir, quand ce petit monde semble se trouver sous le halo d’un lampadaire et que le reste est plongé dans la pénombre.
Cette barre est de bonne facture. Elle est solidement amarrée à l’écran sans non plus écraser les quelques pixels sur lesquels elle prend nécessairement appui, ce qui était le cas de celle que j’avais auparavant qui avait eu, de surcroît, le mauvais goût de tomber et d’abîmer l’écran dans sa chute. On trouve aussi une petite molette offrant différents niveaux de luminosité et de températures (ce petit objet est charmant et c’est un plaisir de le manipuler).
Et encore en haut, sur cette même barre, se trouve une webcam 4K, l’Insta360 Link 2 dont les performances sont incroyables. Il m’a fallu faire l’acquisition d’un petit support supplémentaire pour la jucher sur cette barre. Je ne crois pas avoir jamais eu une aussi bonne webcam, et celle intégrée au MacBook croupit depuis dans la honte et l’abandon.
Autre source d’éclairage, une lampe Ikea que j’ai couplée à une prise connectée Meross, en attendant que les ampoules connectées reviennent de Hong Kong. À proximité de cette lampe, se trouve un petit chargeur UGREEN magsafe rechargeant l’iPhone et les AirPods Pro, éliminant le besoin de deux disgracieux câbles. Le chargeur magnétique est rotatif, ce qui permet, de temps à autre, d’afficher ces gros widgets qui permettent de garder un œil sur l’heure ou le calendrier, fonction que j’aimerais penser à utiliser plus souvent, surtout depuis que MacOS Sonoma propose d’afficher et d’interagir avec son iPhone directement sur le Mac.
En tout cas, puisque ledit MacBook est sur un pied (d’estal), déporté sur la droite, il faut bien, face à l’écran Dell, un clavier et une souris. Le clavier est un LogiTech MX, sans fil et rétroéclairé. Je l’avais acheté parce qu’un bouton permet de le connecter à trois appareils différents, mais je l’aime tellement qu’il a réussi à me faire délaisser le clavier d’Apple (qui a pourtant l’avantage de Touch ID) et qu’il trône désormais au centre du bureau. En revanche, j’ai gardé le Magic Trackpad.
Avant de décrire le reste, je dirais tout de suite qu’il manque quelque chose sur ce bureau. C’est un hub Thunderbolt qui me permettrait de ne brancher qu’un câble sur le Mac et tout le reste dessus, mais ça sera pour une autre fois. Ça sera en tout cas un achat drôlement utile parce qu’il y a de plus en plus de trucs à brancher sur ce bureau, au premier chef duquel on trouve un disque dur LaCie qui me permet de faire quelques sauvegardes manuelles (feux mes Google Drive et mon compte Obsidian) et automatiques (Time Machine). Et dans les trucs à brancher, on trouve le petit dernier arrivé sur ce bureau, le RØDE PodMic, micro à moins de 100 euros (le Shure SM7B en vaut près de 400). L’interface audio est le Focusrite Vocaster One et le bras, l’élégant Elgato dont le nom m’échappe.
Sur ce bureau, on verra encore un iPad mini qui ne s’y trouve que pour des raisons qui m’échappent la plupart du temps, si ce n’est pour le brancher (sur un petit chargeur UGREEN). Je crois que j’aime particulièrement me concentrer sur un seul écran (dit le type qui pense parfois acheter un deuxième écran Dell), et par conséquent je n’utilise pas l’iPad quand je suis au bureau (sauf exception du genre prise de notes avec Notability et le stylet). Concernant le rôle que joue cet iPad mini dans ma vie numérique, je ne détaille pas plus, car je l’ai fait en une dizaine de podcasts.
Que conclure ? On l’a vu. Un hub Thunderbolt sera clairement le bienvenu. Je retrouverai bien mes Homepods mini également qui se nichent encore dans des cartons. Peut-être passerai-je au bureau assis-debout un de ces jours, mais pour le moment je suis plutôt bien assis chez moi (sur une chaise Ikea LÅNGFJÄLL). Les 27 pouces de l’écran me satisfont dans l’ensemble, mais c’est parfois un peu juste. On verra. Ce qui est sûr, c’est que ce tout petit monde évoluera encore au gré des besoins et des évolutions technologiques.
À suivre.
P.-S. Les liens Amazon sont des liens sponsorisés.
NaNoWriMo vient de publier une FAQ expliquant qu’ils ne rejettent pas l’utilisation de l’IA dans le processus d’écriture et ils qualifient même son rejet de "classist" et "ableist", que je ne sais trop comment traduire autrement que par des périphrases : le rejet de l’IA relèverait soit d’une discrimination de classe soit de personnes présentant un handicap.
Et je dois dire que, pour moi, cela a du sens parce que la maîtrise des lettres a toujours constitué une aristocratie (et l’orthographe, de l’aveu de l’Académie française à la création de son dictionnaire le disait ouvertement). Elle représente une distinction de classe. Par exemple, avant que la quasi totalité que la population sache écrire, on avait recours à un écrivain public pour écrire une lettre. D’aucuns ont parfois recours à un « nègre » (mais je préfère l’équivalent anglais de « ghost writer »). On rencontre un problème similaire de classe quand un élève a les moyens d’avoir un tuteur personnel ou pas. L’IA risque de mettre tout le monde a égalité, pourvu qu’on apprenne à nos élèves à écrire avec l’IA et non que celle-ci écrive à leur place. Quant aux questions d’accessibilité, elles sont mentionnées dans l’article. Un utilisateur explique qu’il s’implique davantage dans les communautés en ligne car l’IA l’aide à mieux formuler ses idées.
Reste que beaucoup d’écrivains ou scénaristes sont furieux et à juste titre (surtout quand on pense que les IA sont entraînées sur le travail des écrivains qu’elles sont susceptibles de remplacer), mais je trouve assez ironique cette réponse de l’un d’eux :
"Generative AI empowers not the artist, not the writer, but the tech industry. It steals content to remake content, graverobbing existing material to staple together its Frankensteinian idea of art and story," wrote Chuck Wendig, the author of Star Wars: Aftermath, in a post about NaNoWriMo on his personal blog.
Ce n’est pas faux, mais l’art est-il autre chose que ce processus « frankensteinien », de reproduction d’un contenu à l’envi ? La Fontaine ne disait pas autre chose : « Nous ne saurions aller plus avant que les Anciens : ils ne nous ont laissé pour notre part que la gloire de les bien suivre. » Et concernant Star Wars, on suit le précepte. On suit les anciens. Mais alors, qu’y a-t-il d’original dans la déclinaison interminable d’un scénario qui a vu le jour dans les années 70 ? Certes, on a fait la même chose avec le roman de Renart, le cycle arthurien et probablement la bible (mais aussi parce qu’on n’avait pas ce problème de droits d’auteur), mais peut-on faire de ce sempiternel recyclage l’apanage de l’être humain ? Peut-on penser qu’on est vraiment créatif en se racontant encore et encore des histoires de Jedis ? Parce qu’il faut quand même reconnaître que les scénaristes ne sont pas tous des La Fontaine.
En fait, il apparaît que la machine peut aisément faire ce qu’ils font et à part le scandaleux entraînement des IA sur un matériel protégé par le droit d’auteur, je ne vois pas le problème. On se souviendra juste à quel point nos productions sont stéréotypées, aisément pastichables, ce que l’on voit bien avec la musique. Suno est une IA qui vous permet de créer des morceaux de musique en deux clics. La raison pour laquelle cela marche si bien – et c’est vrai de toutes les IA – c’est parce que nous sommes prédictibles. Un morceau de musique ? Vous prendrez bien un peu de binaire avec couplet/refrain ? Même chose avec le langage. On produit tous un charabia de phrases toute faites, mêlange de locutions à la construction plus ou moins heureuses (« au jour d’aujourd’hui, on est en capacité de blablabla ») voire de proverbes d’une sagesse à deux sous.
Concernant la musique, cela me fait toujours penser à Yuval Noah Harari qui disait que l’IA n’aurait pas besoin d’entrer en compétition avec Beethoven mais qu’il lui suffirait de faire mieux que Britney Spears. Et c’est exactement ce qu’il se passe et c’est l’une des raisons pour lesquelles tant d’individus voient l’IA d’un si mauvais œil, mais ce peut être aussi une magnifique opportunité de placer la barre plus haut et de nous inviter à faire un peu plus que proposer le 72e épisode de Star Wars (quel que soit le plaisir que j’éprouve à chaque fois, dois-je confesser).
En somme, l’IA met tout le monde à égalité et maintenant que tout le monde a accès à l’écriture, que tout le monde peut s’exprimer sans peur d’exposer une orthographe défaillante, sans avoir à débourser quoi que ce soit pour trouver une assistance, on peut parier sur une élévation du niveau général. Il faudra juste parier qu’on n’utilisera pas l’IA pour travailler à votre place mais pour nous accompagner.
Et rappelons-nous de ce que concluait Kasparov à la fin de Deep Thinking :
We have other qualities the machines cannot match. They have instructions while we have purpose. Machines cannot dream, not even in sleep mode.
Nous avons des objectifs et des rêves. L’IA peut bien nous aider à les mettre en forme. L’inverse n’est pas vrai.
Comme je n’ai pas partagé grand-chose ces derniers temps et que je suis pourtant un grand fervent du partage, laissez-moi vous parler d’un tout petit scénario pédagogique qu’un enseignant ou un élève peut mettre en œuvre très facilement, très rapidement.
Le principe est très simple. Il s’agit de créer de petites devinettes historiques ou littéraires ou biographiques sous forme de vidéo. Ça marche comme ça.
Demandez à chatGPT la chose suivante : Je veux que tu crées en trois phrases une courte description biographique qui se terminera par « Qui suis-je ? » permettant de donner de petites devinettes aux élèves. Commence par Napoléon.
Ce à quoi l’IA répond : « Je suis né en Corse en 1769 et je suis devenu empereur des Français en 1804. Je suis connu pour mes campagnes militaires à travers l’Europe et pour avoir codifié les lois avec un Code qui porte mon nom. Qui suis-je ? »
Ensuite, direction Hedra avec lequel on va créer notre petite devinette historique sous forme de vidéo.
On peut taper son propre texte et utiliser les fonctions text to speech mais le français n’est pas proposé. J’ai donc fait lire le texte à TTSMaker et importé dans Hedra le texte produit par chatGPT (le mieux est d’utiliser sa propre voix, mais ça m’amusait d’utiliser l’IA de bout en bout).
Ensuite, on ajoute une image (je suis allé cherché sur Wikimédia ce dont j’avais besoin).
On génère la vidéo. Et c’est rigolo.
Je me suis amusé à ajouter des sous-titres. J’ai donc téléchargé ma vidéo produite avec Hedra, envoyé le tout sur CapCut et voilà le résultat. Encore une fois, facile et rigolo.
Je placerai certainement ce scénario dans une formation dédiée à l’IA en histoire/géo. En attendant, je vous le propose tel quel. C’est aussi une excellente occasion d’évoquer (grâce aux sous-titres) les questions d’accessibilité et d’inclusion. Enfin, gardons à l’esprit qu’on peut insérer la vidéo dans un quiz pour récolter les réponses.
Cet été, Itinéraire d’un lecteur gâté, ce n’est plus seulement un podcast ni un article de blog. C’est maintenant aussi un livre au format ePub que vous pouvez télécharger gratuitement.
En somme, vous pouvez lire et écouter les dix épisodes sur ce blog (ou sur Apple Podcast ou encore Spotify), mais vous pouvez à présent lire Itinéraire d’un lecteur gâté sur votre tablette ou liseuse favorite.
Cela faisait un moment que je voulais à nouveau m’essayer à construire un tableau du type Excel ou Google Sheets me permettant, à l’aide de l’intelligence artificielle, de générer des appréciations, non pas pour écrire des bulletins à ma place, mais pour m’assister dans la tâche d’analyse de données toujours plus nombreuses.
Voici comment ça s’est passé et de quelle façon je m’y suis pris.
En lisant le Times
Dimanche dernier, je lisais dans le Times un article intitulé AI could help save the NHS — but not in the ways you may think. On pouvait y lire que les médecins passent un temps considérable à rédiger de la paperasse administrative et à mettre en forme les notes qu’ils prennent après une consultation pour le suivi de leurs patients.
Dom Pimenta, a 36-year-old cardiologist and the founder of Tortus, said: “If you look at the maths, up to 60 per cent of the time is spent with computers, which means 40 per cent of the time is spent with patients.
“If you get that computer time down to 15 per cent, you are getting 85 per cent of the time with patients. Imagine what the NHS could do with that many more doctors or nurses.” 1
L’IA pourrait donc aider les médecins à réduire ce temps qu’ils pourraient ainsi consacrer à leurs patients plutôt que de s’asseoir devant leur ordinateur.
Je ne suis pas allé explorer ce que propose Tortus (« Doctors, not data clerks », ai-je pu toutefois entrapercevoir), mais je comprends à la lecture de l’article qu’il s’agit d’une IA qui pourrait « écouter » durant la consultation et rédiger automatiquement une synthèse, ce qui ne va pas sans poser différents problèmes en termes de vie privée, mais passons.
L’être humain et la machine
Je trouve cela très intéressant parce que l’article fait valoir que l’adoption de l’IA sera lente à pénétrer le domaine médical pour de nombreuses raisons, mais aussi parce que de toutes les merveilles que notre technologie peut produire, celle qui a le plus de chance d’être rapidement adoptée est cette modeste tâche de suppléer l’être humain dans ses fonctions administratives et non de le remplacer. En somme, les brillantes technologies que des Oppenheimmer repentis nous annoncent comme susceptibles de mettre fin à l’humanité sont en train de rentrer par la petite porte de la prose administrative plutôt que celle du grand remplacement par des IA aux commandes de scanners automatisés. Intéressant, non ? In fine, c’est la même histoire depuis Kasparov et qui, dans les réflexions subséquentes du champion, a donné naissance à l’image du centaure et que l’auteur de Co-Intelligence semble reprendre à son compte sous une autre appellation.
Mais je me suis dit que, de fait, il en allait de même avec les enseignants. Comment faire pour qu’ils passent plus de temps avec leurs élèves plutôt que d’écrire des mails ou des bulletins ? Comment leur permettre d’accélérer toutes les tâches qui les rapprochent de leur ordinateur et les éloignent de leurs élèves ? On peut acheter, s’abonner, télécharger un tas de trucs, mais n’est-ce pas un peu dommage ? Ne peut-on profiter de cette brillante technologie pour bâtir soi-même ses propres outils ? Je me suis alors rappelé qu’il y avait quelque chose à faire même si mes compétences en matière de code sont désastreuses. Après tout, ne suffit-il pas de demander à chatGPT ? C’est ce que j’ai fait (la conversation peut être consultée en cliquant sur ce lien).
Un tableur pour aider dans la rédaction des appréciations
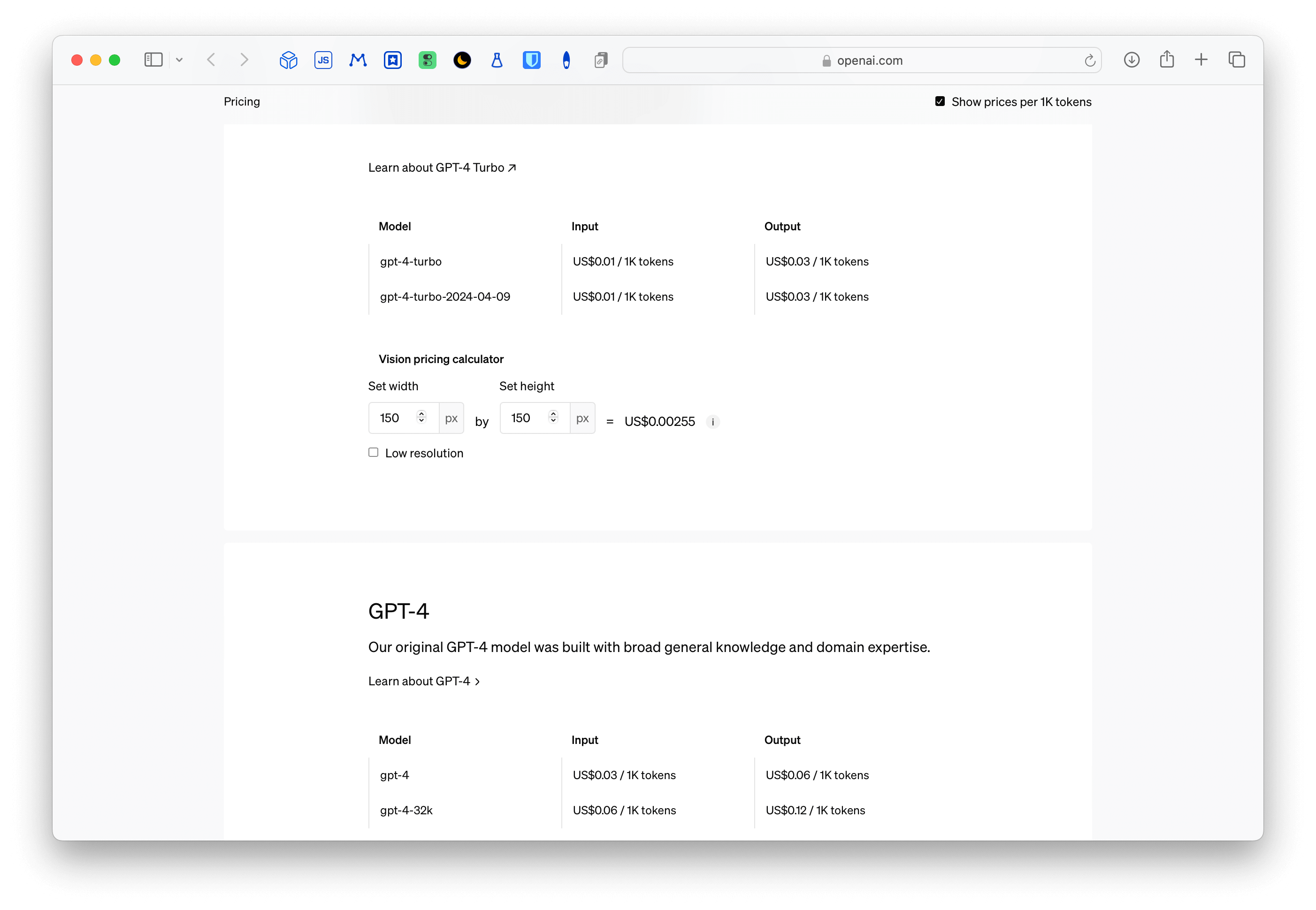
Pour mon premier essai, j’ai demandé à chatGPT d’écrire un script pour Google Sheets permettant d’utiliser l’API d’OpenAI. Compte tenu du faible coût que cela représente, on pourrait imaginer investir dans ce genre de choses plutôt que des abonnements à 20 euros le mois. Comme on peut le voir ci-dessous, le coût du token (pour GPT 4) est de $0.003.
Bref, assez rapidement, j’ai eu mon script que voici (après quelques essais/erreurs).
const OPENAI_API_KEY = 'Insérer votre clé';
const OPENAI_API_URL = 'https://api.openai.com/v1/chat/completions';
/**
* Submits a prompt to GPT and returns the completion
*
* @param {string} prompt Prompt to submit to GPT
* @param {float} temperature Model temperature (0-1)
* @param {string} model Model name (e.g., gpt-4)
* @param {int} maxTokens Max Tokens (< 4000)
* @return Completion from GPT
* @customfunction
*/
function GPT(prompt, temperature = 0.6, model = 'gpt-4', maxTokens = 256) {
var data = {
model: model,
messages: [{"role": "user", "content": prompt}],
temperature: temperature,
max_tokens: maxTokens
};
var options = {
method: 'post',
contentType: 'application/json',
payload: JSON.stringify(data),
headers: {
'Authorization': `Bearer ${OPENAI_API_KEY}`,
'Content-Type': 'application/json'
}
};
var response = UrlFetchApp.fetch(OPENAI_API_URL, options);
var responseData = JSON.parse(response.getContentText());
if (responseData.choices && responseData.choices.length > 0) {
return responseData.choices[0].message.content.trim();
} else {
return 'No response from OpenAI API';
}
}
/**
* Submits examples to GPT and returns the completion
*
* @param {Array<Array<string>>} examples_input Range of cells with input examples
* @param {Array<Array<string>>} examples_output Range of cells with output examples
* @param {string} input Cell to pass as input for completion
* @param {float} temperature Model temperature (0-1)
* @param {string} model Model name (e.g., gpt-4)
* @param {int} maxTokens Max Tokens (< 4000)
* @return Completion from GPT
* @customfunction
*/
function GPT_RANGE(examples_input, examples_output, input, temperature = 0.6, model = 'gpt-4', maxTokens = 256) {
let prompt = `I am an input/output bot. Given example inputs, I identify the pattern and produce the associated outputs.`;
for (let i = 0; i < examples_input.length; i++) {
let example_input = examples_input[i][0];
let example_output = examples_output[i][0];
prompt += `\n\nInput: ${example_input}\nOutput: ${example_output}`;
}
prompt += `\n\nInput: ${input}\nOutput:`;
return GPT(prompt, temperature, model, maxTokens);
}
Pour résumer, tout ce que vous avez à faire est de
créer un compte sur OpenAI, acheter quelques crédits et obtenir une clé API
créer un Google Sheets
aller dans Extensions > Apps Script
coller le code ci-dessus en incluant votre clé API
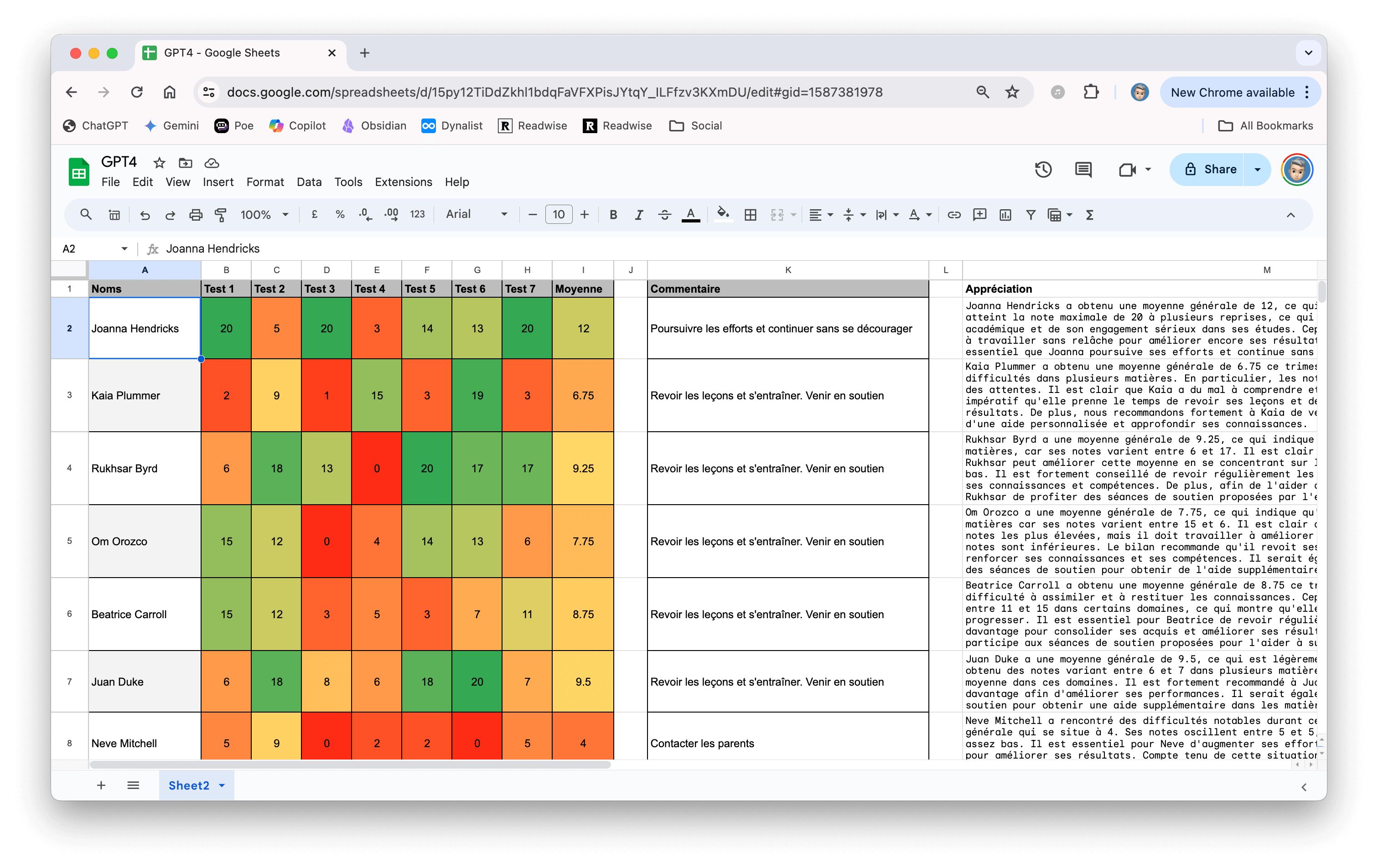
Sur ce modèle, comme vous pouvez le voir sur la capture d’écran ci-dessus, j’ai indiqué plusieurs choses.
Tout d’abord, il y a le noms des élèves (de faux noms évidemment).
Ensuite, il y a des notes (fausses également, générées aléatoirement avec la fonction RANDBETWEEN).
=RANDBETWEEN("0", "20")
Il y a la moyenne des notes (facile).
=AVERAGE(B2:E2)
Un peu de logique maintenant avec une bonne série de IF (histoire d’aider l’IA si besoin) :
=IF(I2 >= 16, "Félicitations!",
IF(AND(I2 <= 15, I2 > 13), "Bon travail !",
IF(AND(I2 <= 12, I2 > 10), "Poursuivre les efforts et continuer sans se décourager",
IF(AND(I2 < 10, I2 > 5), "Revoir les leçons et s'entraîner. Venir en soutien",
"Contacter les parents"
)
)
)
)
Et enfin, notre GPT (c’est en fait le prompt qui marche uniquement parce que nous avons inséré le script ci-dessus).
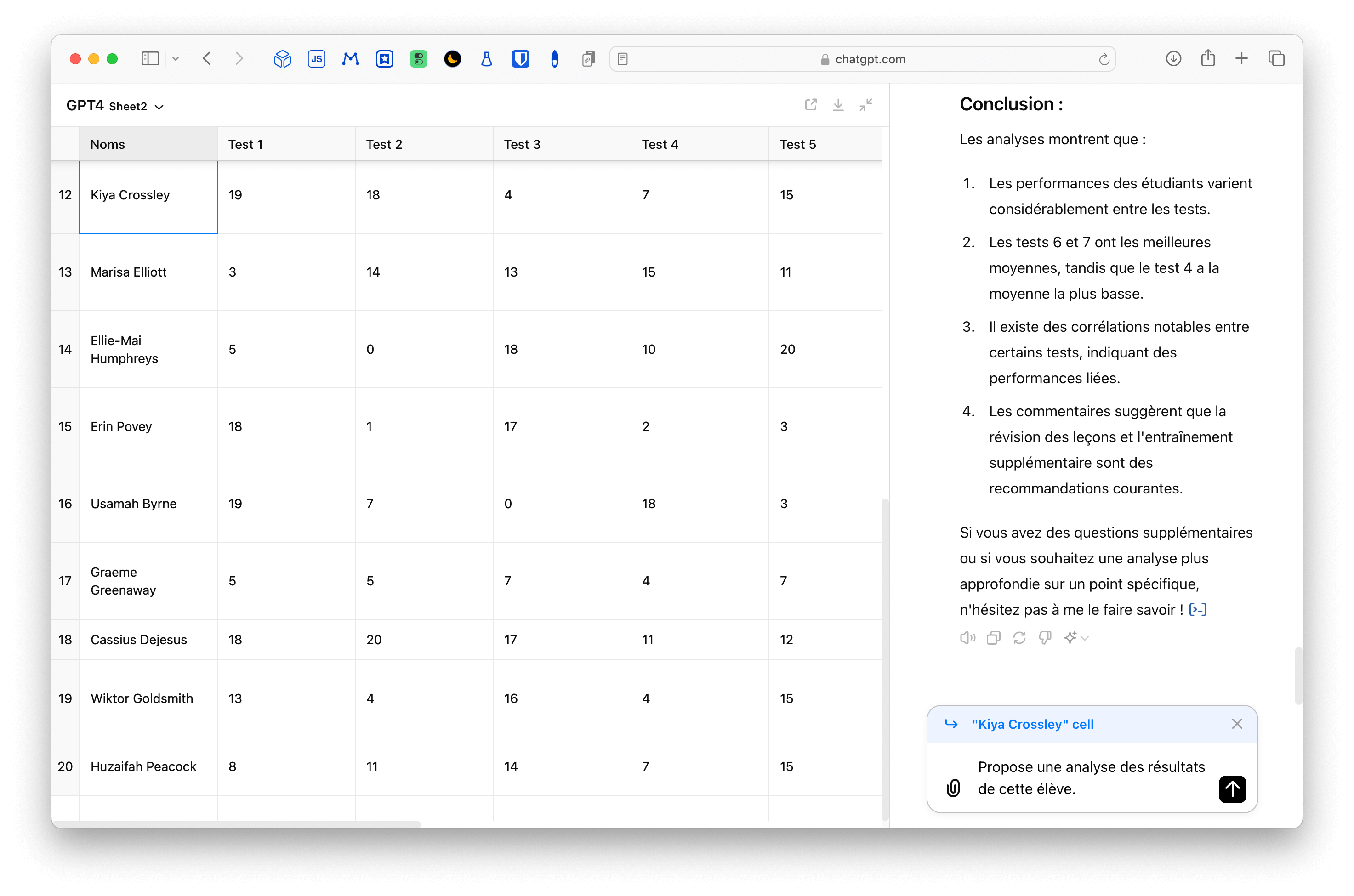
=GPT("Écris le bulletin de cet élève en 4 ou 6 phrases pour '"&A2&"'. Prends en considération la moyenne des notes se trouvant en '"&I2&"' ainsi que les notes se trouvant de '"&B2&"' à '"&H2&"' ainsi que le bilan en '"&K2&"'")
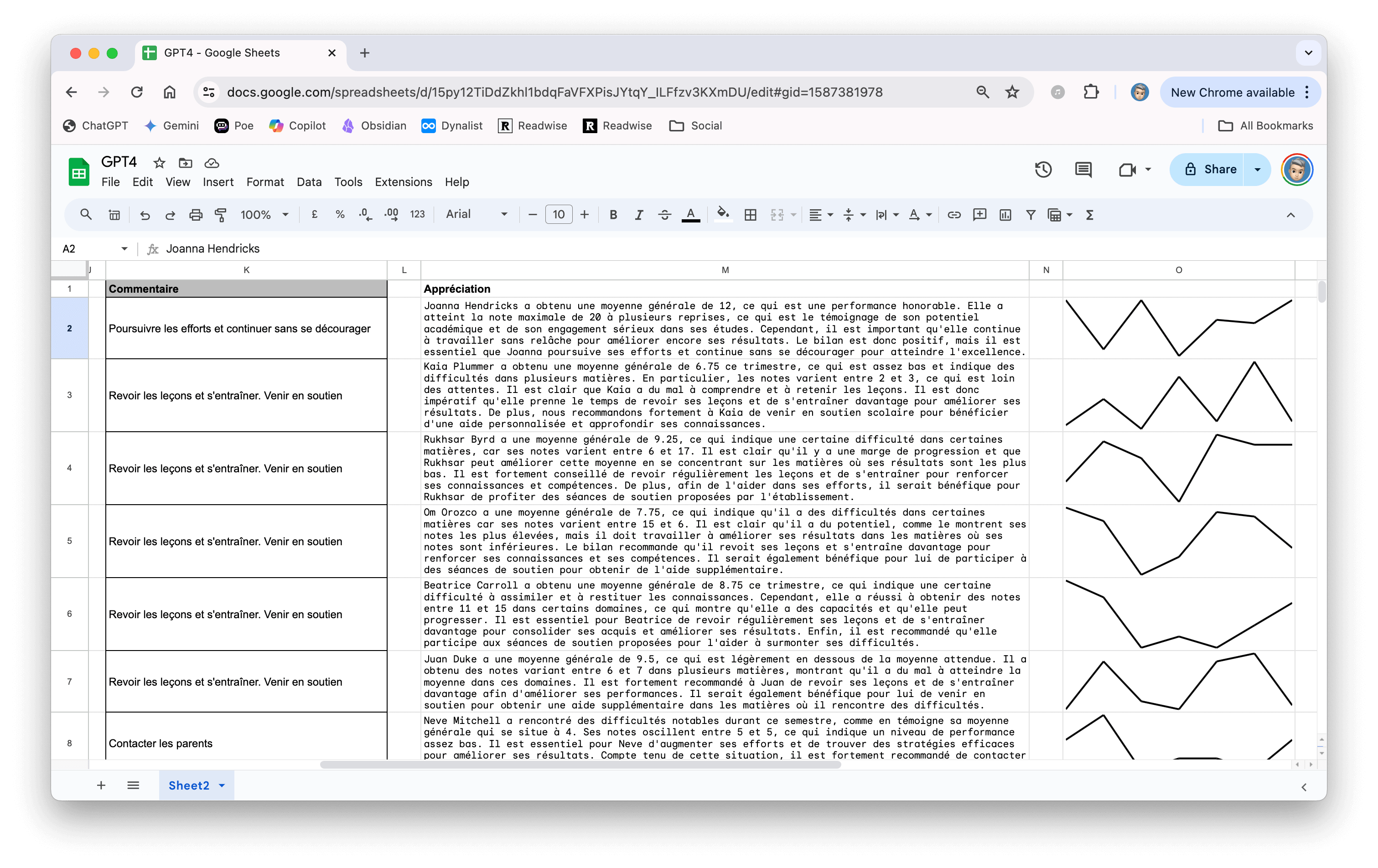
Vous remarquerez que je me suis aussi amusé à insérer un petit graphique qui indique la progression.
=SPARKLINE(B2:H2, {"linewidth", 2})
Et enfin vous voudrez bien vous rappeler que notre stochastic parrot n’a pas pour fonction de vous remplacer ni d’écrire les bulletins à notre place, mais de générer (en plusieurs versions si nécessaire) des conseils et analyser des résultats qu’il vous revient de relire, corriger, compléter et assumer puisqu’en dernière instance, vous restez l’auteur et que c’est votre responsabilité qui est engagée. Enfin (encore), on gardera à l’esprit que l’IA est très, très forte pour produire le même verbiage creux dont nous avions auparavant la gênante exclusivité et qui est donc maintenant capable, comme un enseignant qui au comble de l’ennui et qui aurait déjà rempli 237 bulletins, d’écrire des banalités du type « Doit se mettre au travail blablabla ».
Je dis souvent à qui veut l’entendre quand on m’interroge sur le sujet qu’il faut considérer que l’IA vous assiste, mais ne se substitue pas à vous. Elle le fait à la manière d’un assistant plein de bonne volonté, un jeune assistant, probablement un stagiaire pour lequel il faut tout, mais alors absolument tout relire.
Mais je me suis dit qu’on pouvait continuer longtemps comme ça et j’ai encore demandé des choses à chatGPT.
Votre traitement de texte est votre assistant
Cette fois, l’idée est d’avoir GPT dans Google Docs. Ce n’est pas très original. Gemini rôde déjà par là. Des extensions proposent déjà ce genre de choses, mais en procédant ainsi (c’est-à-dire en faisant les choses soi-même), on l’a dit, c’est très, très peu cher. Une requête est de l’ordre de $0.009 et des brouettes. Et on peut se construire son petit bot selon ses propres besoins (laissez-moi un peu de temps, et je peaufinerai tout cela).
J’en ai fait plusieurs versions. Dans la deuxième, j’ai demandé que GPT soit capable de lire le contenu du document. Voici le script.
const OPENAI_API_KEY = ''; // <- PASTE YOUR SECRET KEY HERE
const OPENAI_API_URL = 'https://api.openai.com/v1/chat/completions';
/**
* Fetch completion from OpenAI API
*
* @param {string} prompt The input prompt for GPT-4
* @param {string} content The content of the Google Docs
* @param {string} model The model to use (e.g., gpt-4)
* @param {float} temperature The sampling temperature (0-1)
* @param {int} maxTokens The maximum number of tokens to generate
* @return {string} The generated completion
*/
function fetchCompletion(prompt, content, model = 'gpt-4', temperature = 0.6, maxTokens = 256) {
var data = {
model: model,
messages: [
{"role": "system", "content": "You are an assistant that helps improve and process text."},
{"role": "user", "content": content},
{"role": "user", "content": prompt}
],
temperature: temperature,
max_tokens: maxTokens
};
var options = {
method: 'post',
contentType: 'application/json',
payload: JSON.stringify(data),
headers: {
'Authorization': `Bearer ${OPENAI_API_KEY}`,
'Content-Type': 'application/json'
}
};
var response = UrlFetchApp.fetch(OPENAI_API_URL, options);
var responseData = JSON.parse(response.getContentText());
if (responseData.choices && responseData.choices.length > 0) {
return responseData.choices[0].message.content.trim();
} else {
return 'No response from OpenAI API';
}
}
/**
* Process the content of the Google Doc with OpenAI API
*/
function processContent() {
var doc = DocumentApp.getActiveDocument();
var body = doc.getBody();
var content = body.getText();
var prompt = DocumentApp.getUi().prompt('Enter your prompt for GPT-4').getResponseText();
var processedContent = fetchCompletion(prompt, content);
body.appendParagraph('\nProcessed Content:\n');
body.appendParagraph(processedContent);
}
/**
* Create a custom menu in the Google Docs UI
*/
function onOpen() {
DocumentApp.getUi().createMenu('GPT Assistant')
.addItem('Process Content', 'processContent')
.addToUi();
}
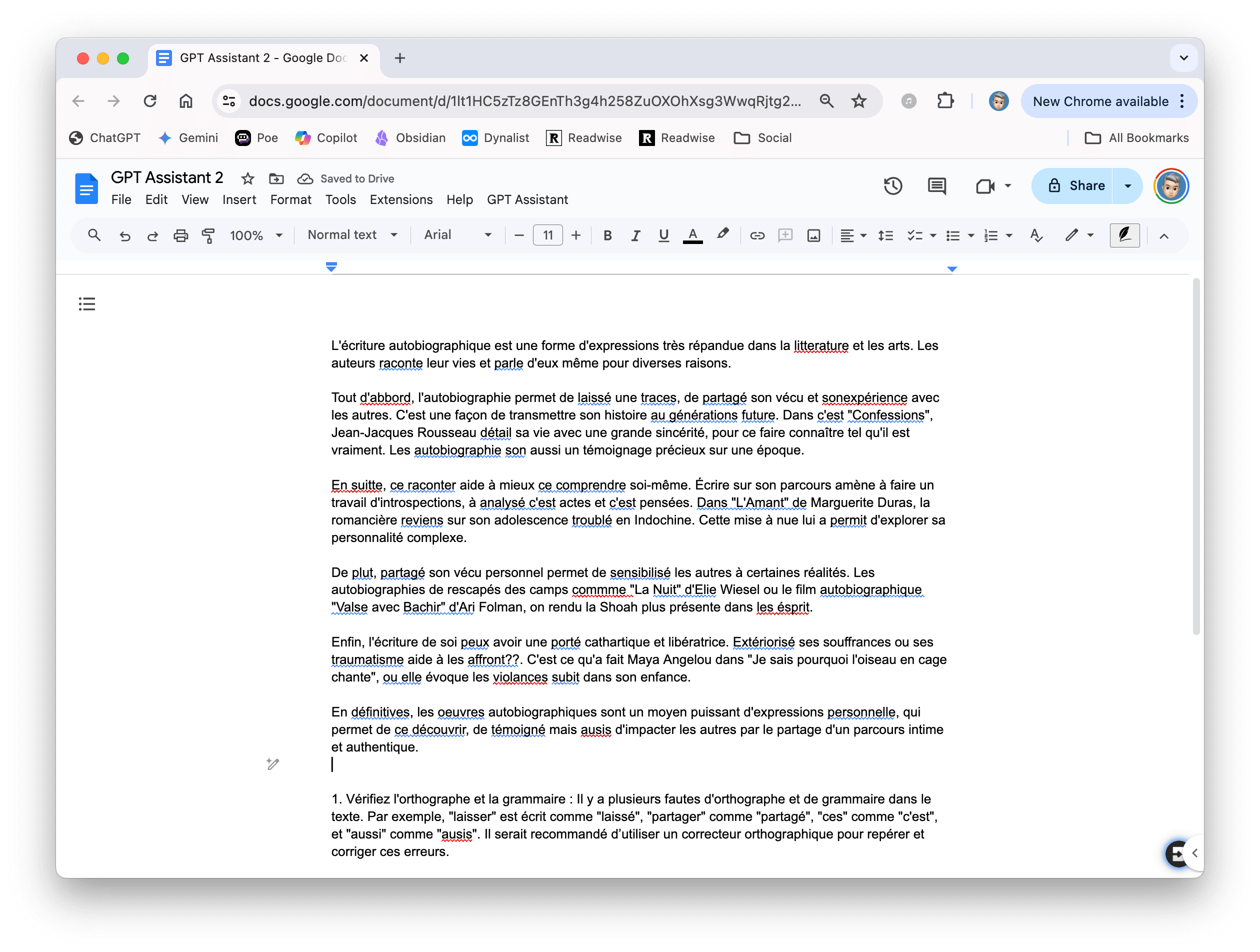
Voici le prompt que j’ai utilisé pour corriger une rédaction (générée par Claude qui, avec complaisance, a ajouté pas mal d’erreurs d’orthographe que chatGPT n’a qu’une envie, c’est de corriger) :
Propose des conseils de correction sur ce texte écrit par une élève de collège (troisième dans le système français). Ne corrige pas le texte, propose juste quelques conseils pour que l’élève améliore son travail.
Évidemment, si la chose vous dit, vous pouvez demander à chatGPT de créer un add-on pour vous. C’est plus riche et plus complet. Plus interactif aussi. Bref, assez rigolo. Il y a juste une étape supplémentaire qui consiste à créer un fichier HTML.
const OPENAI_API_KEY = ''; // <- PASTE YOUR SECRET KEY HERE
const OPENAI_API_URL = 'https://api.openai.com/v1/chat/completions';
/**
* Fetch completion from OpenAI API
*
* @param {string} prompt The input prompt for GPT-4
* @param {string} content The content of the Google Docs
* @param {string} model The model to use (e.g., gpt-4)
* @param {float} temperature The sampling temperature (0-1)
* @param {int} maxTokens The maximum number of tokens to generate
* @return {string} The generated completion
*/
function fetchCompletion(prompt, content, model = 'gpt-4', temperature = 0.6, maxTokens = 256) {
var data = {
model: model,
messages: [
{"role": "system", "content": "You are an assistant that helps improve and process text."},
{"role": "user", "content": content},
{"role": "user", "content": prompt}
],
temperature: temperature,
max_tokens: maxTokens
};
var options = {
method: 'post',
contentType: 'application/json',
payload: JSON.stringify(data),
headers: {
'Authorization': `Bearer ${OPENAI_API_KEY}`,
'Content-Type': 'application/json'
}
};
var response = UrlFetchApp.fetch(OPENAI_API_URL, options);
var responseData = JSON.parse(response.getContentText());
if (responseData.choices && responseData.choices.length > 0) {
return responseData.choices[0].message.content.trim();
} else {
return 'No response from OpenAI API';
}
}
/**
* Process the content of the Google Doc with OpenAI API
*/
function processContent(prompt) {
var doc = DocumentApp.getActiveDocument();
var body = doc.getBody();
var content = body.getText();
var processedContent = fetchCompletion(prompt, content);
body.appendParagraph('\nProcessed Content:\n');
body.appendParagraph(processedContent);
}
/**
* Show the sidebar for user input
*/
function showSidebar() {
var html = HtmlService.createHtmlOutputFromFile('Sidebar')
.setTitle('GPT Assistant')
.setWidth(300);
DocumentApp.getUi().showSidebar(html);
}
/**
* Create a custom menu in the Google Docs UI
*/
function onOpen() {
DocumentApp.getUi().createMenu('GPT Assistant')
.addItem('Open GPT Assistant', 'showSidebar')
.addToUi();
}
Vous pouvez télécharger le modèle si cela vous intéresse. N’oubliez pas que Google vous prévient 20 fois qu’il y a un script attaché et qu’il convient d’être prudent.
Je ne les inclus pas dans ce billet de blog, mais je continue mes essais. chatGPT est en train de construire pour moi une extension pour Gmail et je fais aussi joujou avec l’API de Claude dans le même temps (pour comparer). Au reste, j’apporterai quelques améliorations à ces documents notamment au tableur permettant de générer des appréciations, car on peut faire encore bien mieux.
Je vous tiens au courant.
P.S.
On peut depuis peu connecter son compte Google ou Microsoft à chatGPT et donc demander au bot d’analyser notre tableau. Je dois dire que c’est assez impressionnant (mais plus cher que notre solution). À suivre.
Mise à jour du 31/05/2024
Poursuivant mes expérimentations avec l’API d’OpenAI et Google Sheets, j’ai tenté deux choses, certes imparfaites, mais que je crois sinon intéressantes du moins amusantes.
La première, comme on peut le voir dans la vidéo ci-dessus, invite à choisir dans un menu déroulant des appréciations sommaires sur le comportement, les apprentissages, la progression, etc. S’appuyant sur ces brèves observations, GPT produit un commentaire grâce à la même formule (mais je me suis senti obligé de lui faire comprendre qu’il devait se comporter comme un enseignant) :
=GPT("Agis comme un enseignant et écris une appréciation pour cet élève en 4 ou 6 phrases pour '"&A4&"'. Prends en considération les observations se trouvant de '"&B4&"' à '"&H4&"' pour produire cette appréciation.")
Mais comme ces appréciations valent ce qu’elles valent, j’ai eu une deuxième idée. Demandons à l’IA de produire trois versions de ce commentaire initial. J’ai donc créé un deuxième onglet récupérant l’appréciation avec cette fonction :
Et j’invite alors GPT à produire trois versions de ce commentaire.
Version 1 Soutenir et encourager
=GPT("Agis comme un sympathique enseignant passionné et reformule l'appréciation en '"&B3&"' de manière à soutenir et à booster l'ego de l'élève.")
Version 2 Sévère et exigeante
=GPT("Agis comme un enseignant et reformule, sans la contredire mais en variant simplement le point de vue sur le travail fourni, l'appréciation en '"&B3&"' en étant plus sévère et exigeant.")
Version 3 Neutre et factuel
=GPT("Agis comme un enseignant objectif et reformule l'appréciation en '"&B3&"' en étant le plus factuel possible.")
Vous pouvez télécharger le tableur en cliquant sur ce lien.
1 : « Dom Pimenta, cardiologue de 36 ans et fondateur de Tortus, a déclaré : « Si l’on fait le calcul, on constate que jusqu’à 60% du temps est consacré aux ordinateurs, ce qui signifie que 40% du temps est consacré aux patients. Si l’on réduit ce temps d’utilisation de l’ordinateur à 15%, on obtient 85% du temps passé avec les patients. Imaginez ce que la NHS pourrait faire avec autant de médecins ou d’infirmières en plus. »
🎙️ Écoutez cet épisode sur Apple Podcast, Spotify ou ci-dessous si vous le préférez. 👇
Nous voici arrivés au terme de cette réflexion sur la lecture et à ce que celle-ci à y gagner quand elle se pratique sur un écran. Si vous êtes arrivés jusqu’ici, permettez-moi d’exprimer ma gratitude et aussi mon admiration. Vous avez eu la patience de suivre ce récit autobiographique d’un rapport à la lecture tout entier tourné non vers le contenu mais vers le contenant. Vous avez enfin montré un certain intérêt que je ne crois pas être très partagé pour la dématérialisation du livre. Enfin, vous avez eu la gentillesse de suivre un argumentaire qui pourrait se résumer à ceci : non, le livre, contrairement à ce qu’affirmait Umberto Eco, n’a pas atteint une forme indépassable. Oui, sa version numérique offre de nouvelles possibilités. Passons-les en revue une dernière fois et mettons un terme à cette réflexion sur le livre.
Résumons
En abandonnant d’abord les livres papiers puis ma liseuse, j’ai trouvé dans l’iPad une petite machine syncrétique rassemblant sur un seul et même appareil ce qui serait autrement une activité disparate, fragmentée et protéiforme. Ma tablette me procure en effet un accès à toutes les activités de lecture possibles, que celles-ci se fassent au travers des livres, des journaux, du web, des newsletters, des flux RSS, des PDF et autres réseaux sociaux. Mieux encore, elle m’offre les moyens de mémoriser durablement les connaissances que j’engrange. Elle réunit de surcroît en un même objet ce qui permet la lecture et la prise de notes. Ma machine à lire se double d’une machine à écrire.
De fait, lire sur un écran est une activité plus complexe requérant du lecteur le développement de nouvelles compétences pour tirer parti de toutes les promesses de la technologie permettant de plonger dans ses données, les conserver, les trouver, les analyser ou encore les interroger. La lecture est-elle devenue pour autant une affaire de geek ? Je ne le pense pas. La technologie au fur à mesure qu’elle se démocratise devient plus facile d’utilisation, mais précisément il importe d’éviter l’effet Matthieu, et d’éduquer les futurs lecteurs à ces nouveaux usages. Or c’est souvent ce qu’il se passe avec la technologie qui bénéficie en premier lieu aux privilégiés, à ceux qui sont éduqués, à ceux qui ont déjà beaucoup. C’est cela l’effet Matthieu : on donne à celui qui a, et il sera dans l’abondance, mais à celui qui n’a pas, on ôtera même ce qu’il a.
Au reste, contrairement à ce que l’on peut souvent entendre, cette machine à lire ne nuit en rien ni à mes pupilles ni à mes facultés de concentration. Je dirais même que c’est plutôt le contraire et que sans elle, j’éprouve parfois bien des difficultés à consacrer toutes mes facultés d’attention à l’ouvrage à lire.
Mon univers numérique n’est pas pour autant un univers merveilleux, et on a pu voir dans l’article précédent quels étaient les possibles obstacles qui attendent notre lecteur même le mieux intentionné et le mieux équipé. Nous avons entre autres évoqué l’économie de l’attention ainsi que les GAFAM dont la voracité n’est plus à démontrer, luttant de concert pour capter notre attention ivre de contenus brefs, nouveaux, divertissants, superficiels parfois, filtrés par des algorithmes de recommandation le plus souvent mais toujours exerçant un pouvoir, celui de déterminer ce que vous consulterez ou pas. Je pense par ailleurs que les tweets, les shorts, les reels et autres concentrés à consommer à satiété nous éloignent du temps long de la lecture. En outre, ces mêmes GAFAM influent sur ce que nous regardons, entendons et lisons. Mais reconnaissons que ce filtrage de la connaissance n’a pas attendu qu’on s’absorbe dans la contemplation de nos écrans pour sévir et s’exerçait déjà en d’autres temps. Disons simplement que les choses ne vont pas en s’arrangeant, et que l’enjeu démocratique est réel et que le lecteur de 2024 doit faire preuve d’un esprit critique fort pour devenir le citoyen éclairé qu’il aspire à être.
L’avenir du livre
Qu’en est-il du livre papier ? A-t-il d’ailleurs un avenir ? Doit-on avoir un discours résolument tourné vers l’avenir qui fait de la technologie le centre de tout ? La question est d’autant plus légitime que – contrairement à ce que l’on dit souvent et que j’ai longtemps pensé – celle-ci n’est pas neutre et qu’il n’est pas du seul ressort de l’utilisateur d’agir mais que la conception même de tout objet technologique peut être interrogée tant il est vrai que celle-ci incorpore à la fois les valeurs de ses créateurs mais aussi des objectifs qui ont présidé à son développement.
On peut citer l’exemple, parmi tant d’autres, des bancs publics équipés d’accoudoirs que le philosophe Robert Rosenberger qualifie de « technologie contre les sans-abris » puisqu’ils sont conçus pour empêcher les SDF de les utiliser comme lits. La construction matérielle du réel par nos technologies est foncièrement politique, notamment parce qu’elle visibilise certaines choses et en invisibilise d’autres. 1
Mais cela est un autre sujet pour un autre podcast. Toutefois, en ce qui concerne le livre, peut-on seulement dire que la technologie est l’ombilic de notre vie spirituelle ?
En fait, comme le dit Yann Sordet dans Histoire du livre et de l’édition, tout invite à la prudence :
Au seuil des années 2020 le temps semble cependant révolu des « discours radicalement technophiles » et d’une « injonction numérique parfois débridée ». Le constat dominant aujourd’hui est que, dans le livre, la « révolution numérique » désigne une transition plus mesurée que dans d’autres industries culturelles, notamment la musique.
Force est de constater que le livre papier n’a pas disparu et que pour beaucoup de gens, c’est le mode d’accès privilégié de la lecture longue. Et pourquoi pas ? L’important n’est-il pas de lire, quel que soit le support ? Je pense toutefois que les écrans devenant meilleurs (on est loin des écrans à tube cathodique de mon enfance), le confort s’accroissant, ceux-ci devraient continuer à grignoter des parts de marché. Cela se fera lentement et non en supplantant son prédécesseur, en augmentant et donc en diversifiant l’offre. Comme j’ai eu l’occasion de le répéter à l’envi depuis des années, ceci ne tuera pas cela. Les médiums ne s’entretuent pas mais coexistent (la presse, la radio, la télévision, internet…). Ils évoluent certes, mutent profondément à leurs contacts, mais enrichissent notre rapport à la culture plutôt qu’ils ne provoquent l’extinction de celui qui les a précédés.
Cependant, si on moque souvent les témoignages de lecteurs méprisant l’irruption du livre de poche dans les années 50, je crois que ce petit format pourtant bien pratique a contribué, pour une part, au déclassement du livre qui n’a pas grand-chose à perdre dans sa dématérialisation. Certes, il n’a pas mérité une telle responsabilité, et je ne crois pas que le jeune homme interviewé ci-dessus et que l’affirmation qu’il existerait une aristocratie de lecteurs ait quelque fondement, mais je pense que le format ePub peut aussi bien participer à la démocratisation de la lecture que son équivalent de papier. Reste que les bandes dessinées et les albums ou encore les livres d’art trouvent dans les grands formats qu’offrent le papier et les couvertures cartonnées un avantage certain. Ils présentent une beauté matérielle et tangible dont la version numérique est, par définition, totalement dépourvue.
Par ailleurs, comme nous l’avons dit plus haut, nos appareils de lecture continuent de se perfectionner et j’attends avec impatience que les tablettes à encre électronique continuent de gagner en performances, qu’elles soient plus rapides et que l’encre de couleur s’améliore. En somme, que la machine acquière les qualités du papier. Et on y vient, et le succès des dernières Kobo qui semblent se vendre comme des petits pains le montre. Je n’ai pas eu l’occasion de mettre la main dessus, mais je n’ai aucune peine à imaginer que de telles liseuses qui présentent tant de qualités, qui sont faites de matériaux recyclables et qui soient réparables puissent provoquer un certain intérêt. En tout cas, le mien est piqué au vif et la déception provoquée par les liseuses Boox ou les Kindle n’a pas tué dans l’œuf mon souhait de trouver LA liseuse qui pourrait remplacer l’iPad qui malgré toutes ses qualités ne vaut rien en plein soleil sur une plage et qui, le soir, est moins reposant pour les yeux qu’une liseuse.
Mais revenons au papier qui présente un avantage que rien ne semble pouvoir supplanter. En effet, flâner dans une bibliothèque ou une librairie reste impossible numériquement. Le skeuomorphisme n’a jamais apporté de solution convaincante et la vie numérique n’est pas le réel (pardon pour la lapalissade). Pour le dire autrement, je n’ai jamais réussi à trouver des idées de lecture aussi aisément qu’en parcourant les rayons d’une librairie. On sait que celles-ci ont souffert de trois vagues concurrentielles successives : les clubs du livre et la vente par correspondance dans les années 1950, la grande distribution à partir des années 1970 puis la vente en ligne avec l’avènement d’Amazon qui, rappelons-le, a commencé en tant que libraire2. Pour ne pas disparaître, celles-ci sont condamnées à se réinventer, et j’espère qu’elles resteront des lieux de rencontre, d’échanges d’idées même si ce n’est plus là que j’achète mes livres.
Durée de vie des livres numériques
Si les jours du livre papier sont comptés (du moins, quitte à parier, ceux du livre de poche), qu’en est-il des livres numériques ? Sont-ils des supports fiables ?
Pour avoir tenté l’autoédition, je me souviens que l’application que l’on utilise peut du jour au lendemain disparaître. Ce fut le cas d’iBooks Author et j’ai bien retenu la leçon. C’est d’ailleurs la raison pour laquelle j’écris ces lignes avec Obsidian dont le mantra est File over app. Il faudrait citer l’article tout entier, mais bornons-nous à retenir ceci.
If you want your writing to still be readable on a computer from the 2060s or 2160s, it’s important that your notes can be read on a computer from the 1960s.3
Tout ce que j’écris et publie se trouve donc sur des formats accessibles et standards. Mais qu’en est-il des livres ? Même chose. Les livres que je lis sont au format ePub, qui est un standard également. Il va sans dire qu’un tel standard n’a que faire des verrous que les éditeurs lui imposent et je dirais qu’il est de bon ton de savoir comment faire exploser ces verrous. Je ne l’expliquerai pas ici, mais une recherche sur votre moteur favori vous apportera la réponse sans trop d’efforts.
En éliminant les DRM, j’évite de me retrouver dans la situation où je veux benoîtement ouvrir mon livre et constate que celui-ci a disparu de ma bibliothèque car il a été acheté dans une zone géographique différente de celle de laquelle je me trouve en ce moment et que les droits diffèrent. Ne me demandez pas plus de détails. Je n’ai toujours pas compris pourquoi je peux acheter un livre en France mais pas le lire en Angleterre. Cela m’est malheureusement arrivé. On se souvient aussi de ce fâcheux épisode, il y a quelques années, qui avait vu Amazon retirer le livre 1984 des liseuses de ses clients.
J’allais oublier la question des batteries qui revient souvent et dans le fond cela n’est pas vraiment un problème. Elles sont de plus en plus performantes et se recyclent.
Dans le cas d’une bibliothèque, un tel piratage signifie ceci : comme dans la nouvelle de Borges (« La bibliothèque de Babel », Fictions), à la joie d’avoir accès à un lieu contenant tous les livres du monde succède le désarroi de ne pouvoir le parcourir et de s’y retrouver dans un labyrinthe de livres. C’était pareil à la British Library après l’attaque et même des semaines après : on a en principe accès à tous les livres, mais aucun n’est accessible, faute de pouvoir plonger dans les bases de données ou puiser dans les serveurs et ses ressources numérisées puis acheminer les ouvrages.
On voit bien là que se reposer entièrement sur la technologie représente toujours un risque. On l’a vu avec la durée de vie d’un support, on l’a vu aussi quand on ouvre les portes de la fabrique du savoir aux géants de la Silicon Valley, on le voit encore quand les méfaits sont susceptibles de mettre à genoux la totalité des services qu’on utilise quotidiennement.
Mais, il est largement temps de conclure cette longue conclusion.
Lege, lege, relege, labora et invenies
Récemment, je suis tombé sur cette citation sur LinkedIn. La personne s’y référait comme à un adage médiéval : « Lege, lege, relege, labora et invenies ». Le propos est un peu tronqué, car c’est en fait « Ora, lege, lege, relege, labora et invenies », mais peu importe.
En fait d’adage médiéval, la phrase provient d’un livre publié en 1677 donc au XVIIe siècle. Elle signifie « Lis, lis, relis, travaille et trouve ». Du moins, c’est comme ça qu’elle est le plus souvent traduite, mais je trouve qu’« invenire » est un mot intéressant. C’est l’étymologie du mot « inventer ». Saviez-vous que, dans la loi française, celui qui trouve un trésor en est l’inventeur ? Car la chose n’existe pas tant qu’elle n’a pas été exhumée. C’est un peu la même chose avec les idées. À force de lecture et de relecture, on extrait, on invente, on fait venir les choses, on produit des trésors.
De ce point de vue, il n’est pas anodin que la citation latine provienne d’un ouvrage dont le titre est Muter liber, c’est-à-dire le livre muet. C’est un ouvrage d’alchimie, et je ne peux m’empêcher de faire le lien avec l’IA, cette synergie avec l’artifice permettant de produire une véritable intelligence, celle du lecteur. C’est un alliage, celui de la machine et de l’homme, et je n’ai pas la moindre inquiétude pour ce dernier, malgré les démons du numérique, malgré leur main mise sur la culture, malgré les mutations douteuses de notre rapport à la culture, pour peu qu’on n’oublie pas cette vieille injonction, « Lege, lege, relege, labora et invenies ».
3 : Si vous voulez que vos écrits soient encore lisibles sur un ordinateur des années 2060 ou 2160, il est important que vos notes puissent être lues sur un ordinateur des années 1960.
J’ai récemment animé une formation pour l’équipe de lettres du LFI, formation qui ambitionne de montrer comment on peut tirer parti de l’intelligence artificielle pour différencier et notamment, dans le contexte des dernières réformes, faciliter la création de groupes de besoins. La focale portait sur l’écriture de prompts dans Claude dont la version gratuite propose une fenêtre contextuelle de 200k tokens. De quoi s’exprimer ! De ce point de vue, je défends l’idée que plus qu’un art du prompt, c’est un art de la prose qu’il importe de maîtriser et que tout locuteur ou amateur de linguistique reconnaît aisément. C’est la situation d’énonciation, à ceci près que l’allocutaire est une machine qui n’a qu’une idée en tête : vous servir.
Je revendique aussi une certaine sobriété de moyens. Claude peut largement faire votre bonheur. Pas la peine de courir après mille apps. Tout au plus s’est-on autorisé quelques incartades du côté de Brisk, Suno, TTSMaker ou Perplexity.
🎙️ Écoutez cet épisode sur Apple Podcast, Spotify ou ci-dessous si vous le préférez. 👇
Avant de conclure cette série d’articles consacrés à la lecture numérique, arrêtons-nous un moment sur les maux qui accablent le lecteur penché sur sa tablette et qui ne demande pourtant qu’à lire paisiblement, maux que nous avons jusqu’à présent éhontément ignorés. Le lecteur – que nous avons jusqu’ici dépeint comme gâté – peut précisément voire sa lecture se gâter du fait de ces maux, lesquels viennent abîmer la lecture, ce qui ne va pas sans conséquence bien fâcheuses. Mais quels sont ces maux ? Si les cavaliers de l’apocalypse n’étaient que quatre, les annonciateurs de l’Enfer numérique sont ici au nombre de huit. Le double. Rien que ça ! Les voici.
Les publicités et autres messages indésirables
L’infobésité
Les algorithmes de recommandation
Le doomscrolling
L’économie de l’attention
La polarisation
Les fake news
Les hallucinations
Ces maux ont rendu la fréquentation du web compliquée, mais pas impossible à condition de savoir comment les affronter et apprendre à nager en eau trouble. Cette petite liste tératologique peut sembler quelque peu hétéroclite et on pourra justement se demander ce que les uns ont à voir avec les autres. C’est bien simple et nous l’avons dit. D’une façon ou d’une autre, ils perturbent la lecture, la diffèrent, altèrent la qualité de l’expérience, induisent en erreur, vous rendent captifs, vous isolent, vous font errer d’une chose à l’autre que vous n’avez pourtant pas choisies. La liste est interminable.
Passons en revue ces monstres. Mon esprit fonctionnant un peu comme celui de Montaigne (malheureusement, la comparaison s’arrête là), nous procéderons à sauts et à gambades, passant de l’un à l’autre sans autre logique que celle qui amène à ma mémoire le souvenir de ces maux.
Souhaitons leur disparition et, en attendant, voyons également comment les affronter.
Publicités et autres messages indésirables
Quand vous lisez sur le web, la pire des choses (encore que ce classement va s’avérer bien difficile pour savoir à qui donner la priorité dans le pire du pire), c’est probablement la publicité. Je sais bien qu’elle permet à certains de payer le nom de domaine, l’hébergement ou les frais de développement. J’en sais quelque chose. Mais qu’on me permette à mon tour de ne pas l’afficher.
Pour cela, on a vu que le mode lecture de Safari (on retrouve cette fonction sur tous les navigateurs) était un premier moyen. Le second est certainement le désormais traditionnel bloqueur de publicités. On en trouve de nombreux. Il suffit de faire une recherche sur l’App Store. Vous en trouverez plein.
J’utilise pour ma part 1Blocker qui bloque les publicités naturellement, mais aussi toutes sortes d’inconvénients parmi lesquels on trouve au premier chef les cookies et autres trackers en tout genre.
Mentionnons aussi des applications comme StopTheMadness laquelle porte bien son nom et qui vous redonne un peu de contrôle sur ces sites qui, par exemple, bloquent le copier/coller, lancent automatiquement des vidéos… Il y a aussi superagent qui vous débarrasse des pop-ups. Banish bannit une autre forme de pop-ups familière aux utilisateurs d’iPhone et iPad vous invitant à utiliser l’app plutôt que le navigateur. Hush fait quelque chose de similaire en tuant dans l’œuf ces pop-ups qui vous invitent à souscrire ici à une newsletter, là à consentir à un tas de trucs dont vous n’avez que faire. Vous voyez que ce ne sont pas les options qui manquent. Ça n’est jamais parfait. Parfois, il vous faudra désactiver l’une de ces extensions pour que le site fonctionne correctement à nouveau, mais ça en vaut amplement la peine.
Infobésité
Ce mal est terrible et les solutions que l’on peut apporter à ce problème dépendent largement de vous et de votre capacité à accepter que oui, l’information est partout et que non, vous ne pouvez ni tout lire ni tout voir.
En revanche, vous pouvez stocker pour un éventuel plus-tard tel ou tel article. Peut-être ne le lirez-vous jamais, mais vous avez sauvegardé cet article et cela soulage partiellement votre culpabilité. Reste à vous organiser un tout petit peu. On a pu voir que GoodLinks me rendait de fiers services pour cela. C’est ma boite à liens. L’effort minimum consiste à appliquer un tag à l’article sauvegardé, et une étoile à celui qu’il m’importe de lire au plus tôt. Les meilleurs moments pour soulager ma culpabilité liée à mon désir d’information sont toujours ces temps hors-connexion (bien rares il est vrai) où je peux rattraper un peu de mon retard.
J’aime beaucoup aussi le widget sur l’écran d’accueil de ma tablette qui affiche aléatoirement le titre d’un des articles que j’ai sauvegardés et tire ainsi de l’oubli l’un de ces articles enfouis dans une masse sans cesse croissante.
Ma culpabilité se fait hélas cruellement ressentir quand je constate que la liste des articles sauvegardés croît plus vite qu’elle ne décroît, mais à la faveur des vacances, il est parfois possible de soulager ce sentiment bien pénible.
Algorithmes de recommandation
Dominique Cardon, dans À quoi rêvent les algorithmes, nous explique le fonctionnement des algorithmes :
Le futur de l’internaute est prédit par le passé de ceux qui lui ressemblent.
Et il ajoute un peu plus loin :
Ils sont prédictifs parce qu’ils font constamment l’hypothèse que notre futur sera une reproduction de notre passé.
Prédire le futur en fonction de notre passé ! Très concrètement, YouTube agit de cette façon : puisque vous avez regardé une vidéo des Smiths, vous aurez bien envie d’en voir une autre, n’est-ce pas ?
Si vous détestez que l’on vous dise que lire et quoi regarder, fuyez ces réseaux comme feu Twitter qui, au lieu d’afficher chronologiquement les messages des personnes auxquelles vous vous êtes abonné, font apparaître ce qu’ils pensent que peut-être vous seriez intéressé de voir, choix largement dépendant d’algorithmes pas toujours très intelligents, mélanges de likes et de retweets, favorisant les favorisés et créant un espace sans rapport avec celui que vous avez essayé de vous créer. Si l’on y réfléchit bien, il y a là une sorte de contenu éditorialisé. Je ne vois pas d’autres termes pour parler d’un réseau social qui prône la liberté d’expression poussée à son paroxysme et qui laisse passer tweets racistes, sexualisés ou anti wok.
Pour contrer les timelines créées par d’autres, vous pouvez créer des listes. Avant la diaspora qu’a entraîné le rachat par Musk de Twitter, j’avais des listes que je trouvais plutôt riches et informatives. On y trouve malheureusement de la publicité et certaines personnes ont déserté le réseau social autrefois adoré. Mais on peut aller voir sous d’autres cieux comme Mastodon. On peut aussi préférer l’antique flux RSS, et là au moins vous décidez de ce que vous lisez. Si jamais vous avez un abonnement à l’une des plateformes permettant de consulter des flux RSS, vous pouvez mettre en place des filtres qui apporteront également une solution à notre problème qui est l’infobésité. Vous pouvez par exemple interdire certains mots et certains articles n’apparaitront plus.
Rien à voir avec la lecture, mais mentionnons une application comme Freetube qui, si vous détestez les publicités ou justement les recommandations, vous permettra de retrouver un certain plaisir à regarder YouTube. En effet, avec Freetube, nulle publicité ni rien de tout ce qui rend la fréquentation de YouTube pénible.
À noter que, sur iPad, feeeed propose quelque chose de similaire puisque lorsque vous lancez une vidéo YouTube vos yeux et vos oreilles ne font pas l’objet d’un assaut publicitaire visuellement et auditivement navrant qui vous force à regarder un truc qui vous plonge dans des abîmes d’indifférence.
Doomscrolling
J’ai cherché la traduction de « doomscrolling » et ai trouvé « défilement morbide ». Je ne sais pas lequel est le pire (anglais ou français), mais il faut bien reconnaître que les designers du monde entier se sont ingéniés à trouver les moyens de vous faire parcourir des pages et des pages de vidéos ou de textes. Des années de métro et de bus m’ont amené à conclure que cette pratique n’était pas nécessairement l’apanage des jeunes, mais que les « vieux » aussi pouvaient s’adonner à cette pratique abrutissante qui vous absorbe dans la contemplation sans fin d’un contenu avoisinant souvent la nullité totale.
Je ne crois pas particulièrement souffrir de ce problème (sauf période de vide existentiel), mais enfin voilà quelques conseils.
Le mode Concentration offre des possibilités qui méritent d’être explorées. Il vous permet, comme son nom l’indique de vous concentrer sur ce que vous avez à faire et pour vous y aider, vous pouvez choisir de ne plus afficher telle application voire tel écran d’accueil, de supprimer momentanément les notifications et, couplé à Temps d’écran, vous pouvez prendre la mesure du temps que vous passez sur telle ou telle application. C’est une première étape.
Je suis bien d’accord que concernant le dernier point, l’efficacité est maigre et outre un petit sentiment passager de culpabilité, vos efforts pour minimiser votre temps d’écran seront bien vains.
Je serais bien tenté d’essayer une app comme Ochi, mais voilà ! un abonnement supplémentaire ainsi qu’une petite incertitude quant à l’efficacité de tels procédés font que je n’ai pas franchi le pas. Je reste toutefois attentif aux possibilités de contrôle proposées par ces applications, mais si je vois à l’avenir que je peine à contenir ce frénétique besoin de continuer à scroller, je recourrais probablement davantage à ces applications pour limiter la consultation de contenus finalement non choisis.
Au reste, j’ai trouvé dans Wired un article très intéressant intitulé How to Stop Doomscrolling-With Psychology. Dans cet article, on trouve cette non moins intéressante partie intitulée Avoid Confirmation Bias (Éviter le biais de confirmation) et qui démontre que l’on a tendance à discréditer ce qui contrevient à nos opinions.
“Research has shown that humans have a sort of mental filter that causes us to discredit information that challenges what we already believe to be true, and we give more weight to ideas we agree with,” Johnson says. “When you are doomscrolling, you will find there is no shortage of terrible information out there that will only enhance your confirmation bias.” 1
In fine, il nous faut considérer que notre propre vision du monde n’est pas un solipsisme et qu’on ne saurait tout juger à l’aune de nos convictions. Il faut savoir argumenter contre soi-même, se faire l’avocat du diable en somme. Si cette schizophrénie intellectuelle vous effraie, demandez à chatGPT de vous apporter la contradiction.
Économie de l’attention
La démonstration n’est plus à faire et la chose est désormais bien connue. Nous avons un degré d’attention limité et elle représente une potentielle richesse que les différents acteurs de la Silicon Valley s’efforcent de monétiser. En gros, vous avez un service qui est gratuit comme Spotify ou YouTube et vous pouvez soit faire disparaître la publicité en payant un abonnement, soit payer avec votre attention et supporter des discours commerciaux dont la portée intellectuelle est rarement au-dessus du niveau d’un enfant de cinq ans. Cet article du Guardian au titre éloquent, Netflix’s biggest competitor? Sleep, montre bien l’ampleur du problème. En 2017, pour Reed Hastings, le patron de Netflix, son plus gros concurrent n’était pas Amazon ou YouTube, mais le sommeil. On en est là.
Tout aussi inquiétant est la façon dont les algorithmes ou l’interface s’efforcent de vous garder dans l’application. TikTok s’en est fait une spécialité. Vous n’avez même pas à cliquer pour voir une vidéo. Vous êtes déjà en train de regarder. Les J’aime, les titres accrocheurs (clikbait), les recommandations font qu’il est difficile de résister.
Que faire ? Le premier pas consiste à en prendre conscience. Il y faut de la volonté ensuite et cela n’a rien d’évident et malheureusement je n’ai aucune recette miracle si ce n’est celles que nous avons déjà évoquées plus haut.
Polarisation
On la qualifie souvent de politique, mais je trouve qu’elle touche tous les pans de la société et pour prendre un sujet que je connais – celui de l’éducation – je trouve qu’elle touche aussi le corps enseignant. Il n’est que de se souvenir de la réforme du collège en 2016 qui avait divisé en deux camps les enseignants.
Qu’est-ce que le lecteur peut faire ? Multiplier les sources d’information, ne pas se laisser enfermer dans des bulles. Accorder un peu d’attention aux voix dissonantes qui n’abondent pas dans votre sens.
Reste qu’il faut bien connaître qu’avec les réseaux sociaux, on fait l’expérience de l’altérité, et que cela peut être difficile. On se confronte aux opinions d’autrui, lesquelles sont susceptibles de vous heurter. Si cette opinion n’est pas le fruit d’une manipulation (on y vient dans la partie suivante), on peut lui accorder quelque crédit, mais parfois cette opinion n’a pas d’autre objectif que de condamner voire de vous expliquer doctement en quoi vous êtes un sinistre abruti, et toujours lorsque je me trouve dans de tels lieux, je puise ou j’essaie de puiser un peu de sagesse chez les moralistes et notamment La Bruyère qui écrivait :
Parler et offenser pour de certaines gens est précisément la même chose ; ils sont piquants et amers, leur style est mêlé de fiel et d’absinthe, la raillerie, l’injure, l’insulte leur découlent des lèvres comme leur salive ; il leur serait utile d’être nés muets ou stupides, ce qu’ils ont de vivacité et d’esprit leur nuit davantage que ne fait à quelques autres leur sottise : ils ne se contentent pas toujours de répliquer avec aigreur, ils attaquent souvent avec insolence ; ils frappent sur tout ce qui se trouve sous leur langue, sur les présents, sur les absents, ils heurtent de front et de côté comme des béliers ; demande-t-on à des béliers qu’ils n’aient pas de cornes ? de même n’espère-t-on pas de réformer par cette peinture des naturels si durs, si farouches, si indociles ; ce que l’on peut faire de mieux d’aussi loin qu’on les découvre, est de les fuir de toute sa force et sans regarder derrière soi.
Les Caractères, V De la société et de la conversation, 26
J’aimerais assez, au reste, n’être pas le seul à lire cet ouvrage et qu’on érige à nouveau la discussion en un idéal. Citons une dernière fois La Bruyère.
L’on parle impétueusement dans les entretiens, souvent par vanité ou par humeur, rarement avec assez d’attention : tout occupé du désir de répondre à ce qu’on n’écoute point, l’on suit ses idées, et on les explique sans le moindre égard pour les raisonnements d’autrui : l’on est bien éloigné de trouver ensemble la vérité, l’on n’est pas encore convenu de celle que l’on cherche.
Les Caractères, V De la société et de la conversation, 67
Fake news
La chose n’est pas nouvelle. Umberto Eco l’a bien montré dans Six promenades dans les bois du roman ou encore dans Le Cimetière de Prague. Il y montre comment le faux, les thèses complotistes ont eu les pires conséquences. On sait en effet que les Protocoles des sages de Sion ont eu une influence considérable sur l’Holocauste.
Il nous faut en tout cas avoir à l’esprit que nous sommes entrés dans l’ère du soupçon, que tout est potentiellement faux et que l’intelligence artificielle va très certainement industrialiser cette production du faux, mais au moins le lecteur doit-il être averti. Il nous faut enfin éduquer nos élèves et les outiller à apprendre à détecter le faux.
À ce sujet, j’aime bien les propositions d’Asma Mhalla dans son ouvrage Technopolitique et qui explique que nous n’avons pas tous vocation à être des super-experts ou des fact-checkers nés.
Nous devrions nous concentrer non plus sur la recherche viscérale du « vrai », mais plutôt nous demander toujours des choses simples et perdues de vue par la plupart : « Qui », « Qui me parle ? » « D’où me parle-t-on ? » « Qui me dit quoi dans quelle intention ? », autant de questions réflexes bien plus salutaires, plus proactives que celle de savoir si « c’est vrai » ou si « c’est faux ». En lieu et place des injonctions, penser des actions simples mais répétées de politiques publiques qui mettent les citoyens en mouvement, en contrôle, en responsabilité, en désir.
Technopolitique – Comment la technologie fait de nous des soldats
Hallucinations
À ces maux parfois anciens, on en ajoutera un nouveau, l’hallucination. C’est en effet de ce petit nom qu’on désigne les curieuses productions des IA quand au lieu de dire « Je ne sais pas », elles se mettent à inventer. Lors des débuts de chatGPT, l’épisode des œufs de vache a bien faire rire la planète. Il est certes (en partie) réglé, mais l’IA ne continue pas moins d’inventer. J’en ai fait la démonstration récemment à de jeunes élèves. Il suffit de demander une biographie de soi et c’est le grand n’importe quoi.
Llama
Claude
Mistral
Gemini
Yann Houry is a French entrepreneur and computer scientist who has made significant contributions to the field of artificial intelligence. He is the co-founder and CEO of Dataiku, a collaborative data science platform that enables organizations to build, deploy, and manage their own AI models.<br><br>Houry was born in 1984 in France, where he developed an interest in computer science and entrepreneurship from a young age. He went on to study computer science at the École Polytechnique in Paris, where he earned his master’s degree in 2007. After completing his studies, Houry worked as a software engineer at various companies, including Google and Facebook, before co-founding Dataiku in 2013.
Yann Houry est un acteur français né en 1984 à Lille. Il est principalement connu pour ses rôles à la télévision, notamment dans les séries Camping Paradis et Clem. Dans Camping Paradis, il a incarné le personnage de Benjamin Ferreira pendant 10 saisons, de 2006 à 2016. C’était l’un des rôles principaux de la série.<br><br>Depuis 2017, il joue le rôle de Simon dans la série Clem sur TF1. C’est aussi l’un des personnages récurrents de cette comédie familiale. Au cinéma, on a pu le voir dans des films comme La bonne épouse (2017) ou Le meilleur reste à venir (2019). Il a également joué au théâtre, notamment dans L’assassinat de Ernesto G. avec Fabrice Eboué en 2019.
Yann Houry est un réalisateur, scénariste et producteur français. Il est né le 13 novembre 1975 à Paris. Il a suivi des études de cinéma à l’Université Paris 8 et a commencé sa carrière en réalisant des courts-métrages.<br><br>En 2002, il a co-fondé la société de production "Les Films du Worso" avec ses amis de longue date, les réalisateurs Riad Sattouf et Guillaume Brac. Ils ont produit plusieurs courts-métrages, dont "Les Jours où je n’existe pas" de Jean-Charles Fitoussi, qui a remporté le César du meilleur court-métrage en 2004.<br><br>En 2006, Yann Houry a réalisé son premier long-métrage, "Les Amitiés maléfiques", adapté du roman éponyme de Emmanuel Bourdieu.
Yann Houry est un entrepreneur français né le 28 novembre 1973 à Paris. Il est le fondateur et PDG de la société de conseil en innovation et transformation digitale, Fabernovel.<br><br>Après avoir obtenu un diplôme d’ingénieur en informatique à l’École nationale supérieure des mines de Paris, Yann Houry a travaillé dans le secteur de la finance chez Goldman Sachs et chez Morgan Stanley. En 2000, il a rejoint la société de conseil en stratégie McKinsey & Company, où il a travaillé pendant 10 ans.<br><br>En 2010, Yann Houry a fondé Fabernovel, une société de conseil en innovation et transformation digitale.<br>
Là encore, la solution toute relative est de développer la conscience que l’IA est capable d’inventer de toutes pièces des faits. Le cas des œufs de vache était truculent, mais des gens plutôt éduqués se sont fait duper, comme on peut le voir dans cet article du New York Times relatant les mésaventures d’un avocat se reposant naïvement sur les résultats produits par le chatbot. De ce point de vue, je trouve que les propos de Sam Altman, le fondateur d’OpenAI, sont toujours d’actualité.
ChatGPT is incredibly limited, but good enough at some things to create a misleading impression of greatness.
it’s a mistake to be relying on it for anything important right now. it’s a preview of progress; we have lots of work to do on robustness and truthfulness. 2
En somme, on a besoin d’éducation, mais ce n’est pas nouveau.
Que conclure de tout cela ?
On le voit bien. Il n’y a pas qu’une nécessité technologique de s’équiper d’applications bloquant les publicités ou vous permettant de retrouver un peu d’autonomie dans un monde où les algorithmes choisissent pour vous ce que vous allez lire ou regarder. L’enjeu est bien plus grave. Ce qui se joue là n’est rien d’autre qu’une attaque en bonne et due forme de l’esprit au travers de la distribution, de la désinformation et de la manipulation. En somme, c’est une attaque et Asma Mhalla que nous avons déjà citée a raison de rappeler les propos de James Giordano quand il dit « The human brain is the battlefield of the 21st century ». Le cerveau humain est le champ de bataille du XXIe siècle. Et pour bien le comprendre, je ne peux que vous recommander de lire son livre, Technopolitique – Comment la technologie fait de nous des soldats.
Mais je réiterai tout de même ce besoin d’éducation. Et je pense que l’on se fourvoie quand, à l’école, notre seule approche de la lecture est celle des classiques. Qu’on ne s’y trompe pas. Je pense qu’il est important qu’on lise un La Bruyère, mais je pense aussi que développer des compétences de lecture sur des textes certes moins bons mais disons problématiques et qu’il importe d’identifier comme tel est fondamental. Sinon on prendra toujours le risque que le citoyen du XXIe siècle soit désinformé, et on a vu avec la campagne électorale de Donald Trump en 2016 ou la plus récente guerre en Ukraine en quoi démêler le vrai du faux était primordial. L’enjeu n’est rien moins que démocratique.
1 : « La recherche a montré que les êtres humains disposent d’une sorte de filtre mental qui nous pousse à discréditer les informations qui remettent en cause ce que nous croyons déjà être vrai, et à donner plus de poids aux idées avec lesquelles nous sommes d’accord", explique M. Johnson. "Lorsque vous faites défiler des pages indéfiniment, vous vous apercevez que les informations terribles ne manquent pas et qu’elles ne font qu’accentuer votre biais de confirmation ».
2 : « ChatGPT est incroyablement limité, mais suffisamment performant pour donner une impression trompeuse de grandeur. c’est une erreur de s’y fier pour quoi que ce soit d’important pour le moment. il s’agit d’un aperçu des progrès réalisés ; nous avons encore beaucoup de travail à faire en matière de robustesse et de véracité. »
🎙️ Écoutez cet épisode sur Apple Podcast, Spotify ou ci-dessous si vous le préférez. 👇
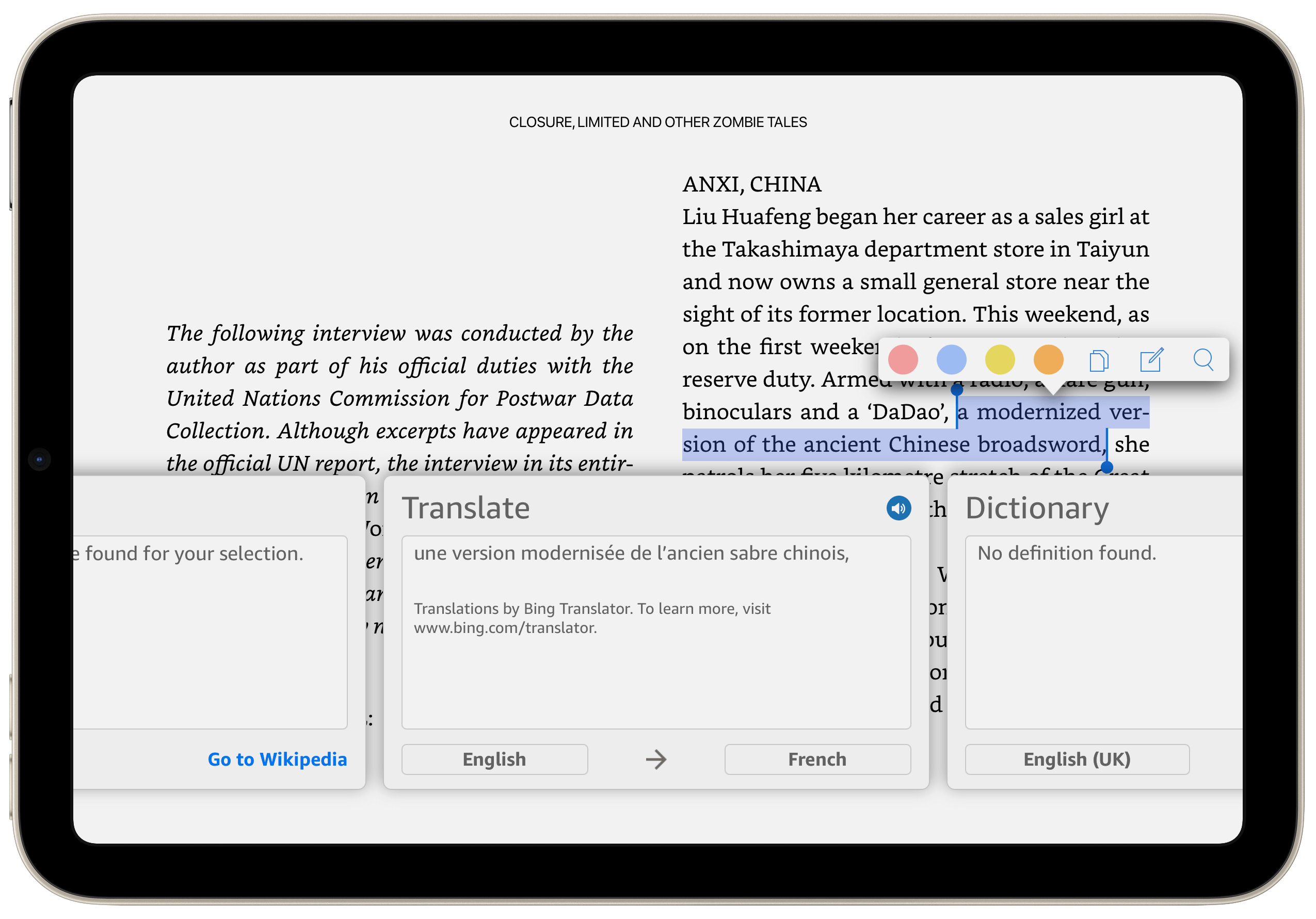
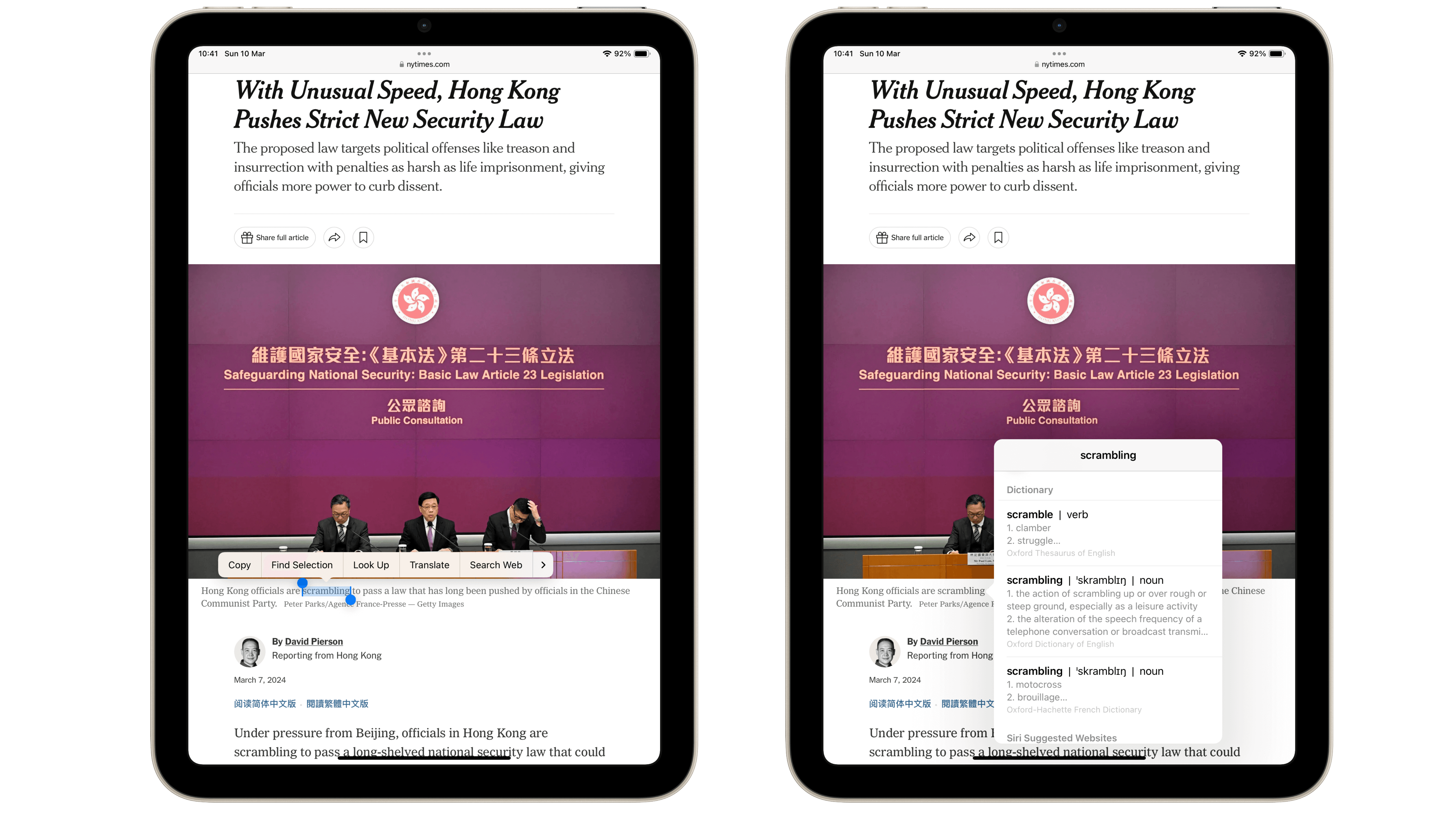
Cette série d’articles ne serait pas complète si on ne consacrait pas une partie aux dictionnaires et autres traducteurs. En ce qui concerne les premiers, je dirais que dans un sujet consacré à la lecture numérique, il est assez évident qu’on mentionne ces traditionnels volumineux ouvrages qu’il était soit pénible de transporter (je ne sais pas s’il existe encore des écoliers qui ont la charge – au sens propre – de leur épais Larousse écorné), soit impossible de transporter (du temps que j’étais étudiant le Trésor de la langue française tenait en plusieurs volumes. Il fallait alors que je me rende à la bibliothèque pour les consulter). Il va sans dire que le numérique permet d’avoir tout ça dans sa poche. On peut ainsi faire ses recherches à toute heure du jour et de la nuit, alors qu’auparavant, il fallait se rendre à la bibliothèque, attendre éventuellement qu’elle ouvre, croiser les doigts pour que l’ouvrage désiré ne soit pas emprunté.
Quoi qu’il en soit, je vous ferai le détail de ce que ma poche contient d’ici quelques lignes, mais auparavant, il me faut en venir au deuxième point de cet article, les traducteurs. Or ceux-ci n’avaient aucun équivalent dans ma vie analogique. Ils n’existaient tout simplement pas. Google Translate n’était pas seulement un rêve. Ce n’était même pas l’embryon d’une possibilité. C’était tout au plus la fantaisie d’un roman de science-fiction ou un appareil magique digne de Star Trek.
Les dictionnaires
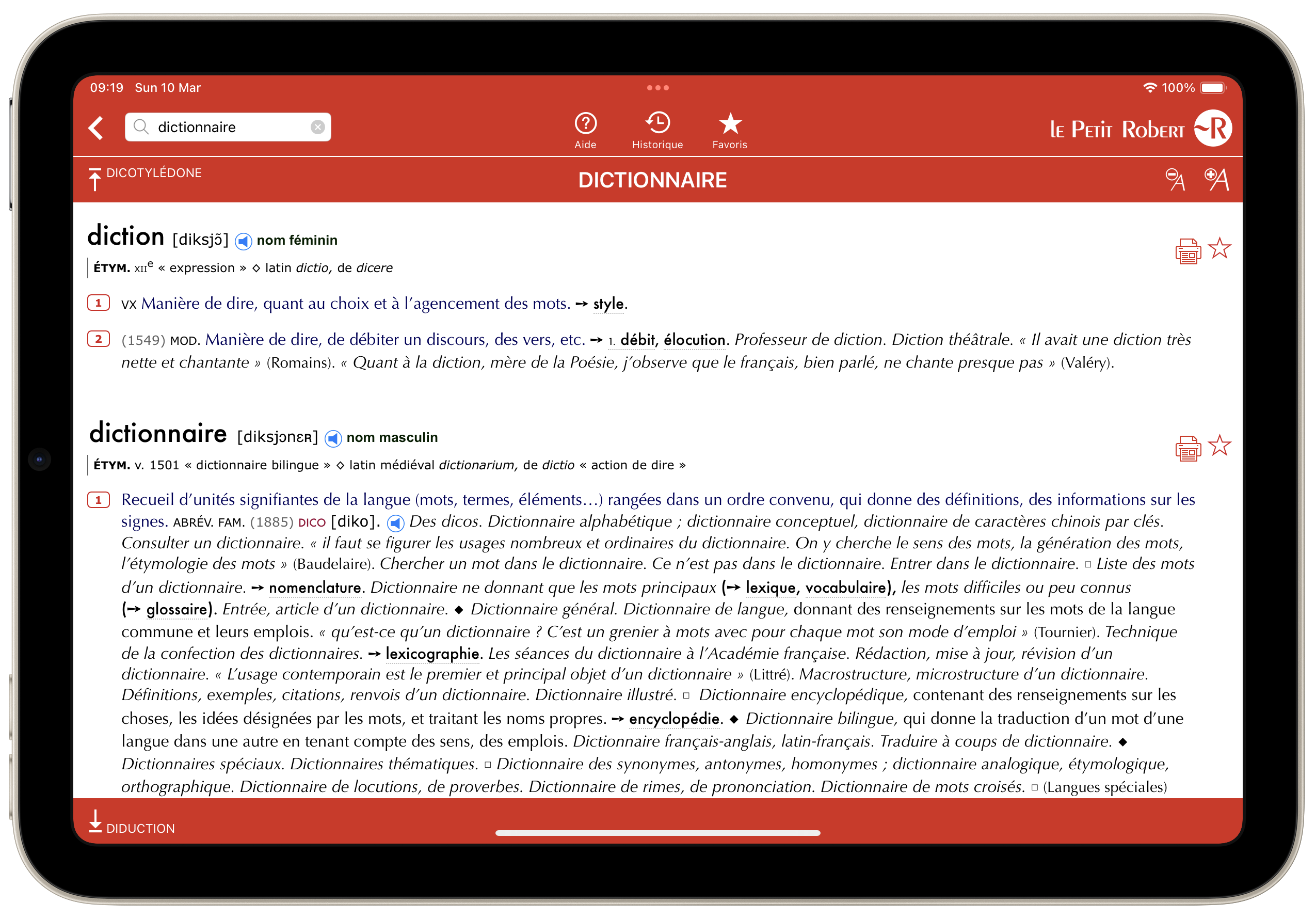
Le petit Robert
La première application que j’ai achetée lorsque j’ai eu mon premier iPad (on devait être en 2012 je crois) a été le Petit Robert. Bien m’en a pris car je bénéficie gratuitement des mises à jour depuis cette année-là, sans que j’aie jamais eu besoin de repasser à la caisse, ce qui ne cesse de m’étonner, tant on s’efforce de vous faire payer et repayer ce que vous avez déjà acheté en ces temps où l’abonnement est la forme de transaction la plus commune. Bref.
Pas grand-chose à dire de son interface certes simple et claire, ni des fonctions qui rendraient l’application absolument indispensable par rapport à sa version papier. On peut bien sûr écouter les mots, ce qui peut s’avérer utile si l’alphabet phonétique reste un mystère pour vous. Reste la recherche intuitive qui peut s’avérer pratique si vous ignorez l’orthographe d’un mot. On a bien l’historique ou la possibilité de créer des favoris, mais rien de transcendant. Rien qui ne permette vraiment de procurer des arguments irréfragables à qui voudrait vous faire abandonner la version papier.
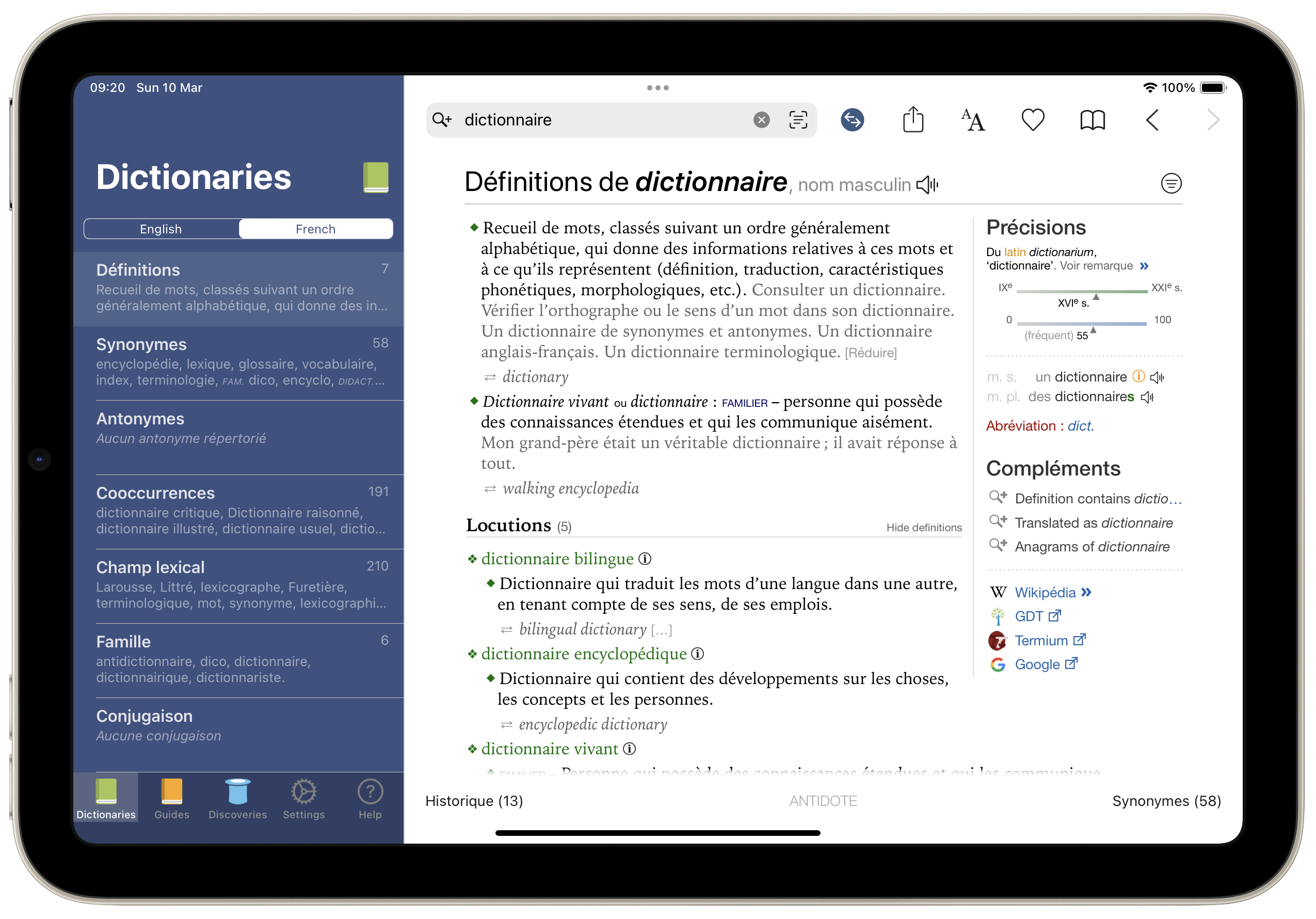
Antidote
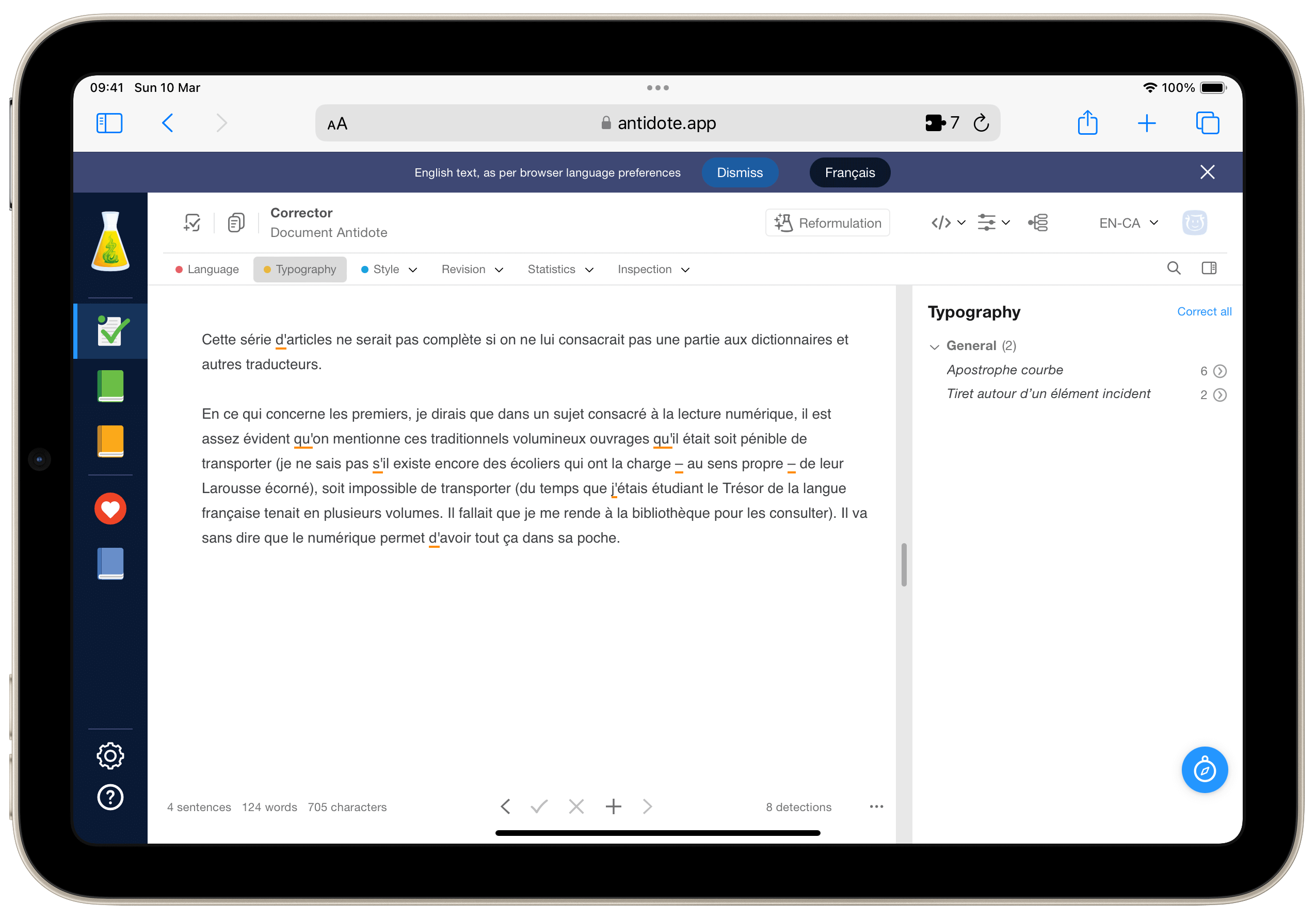
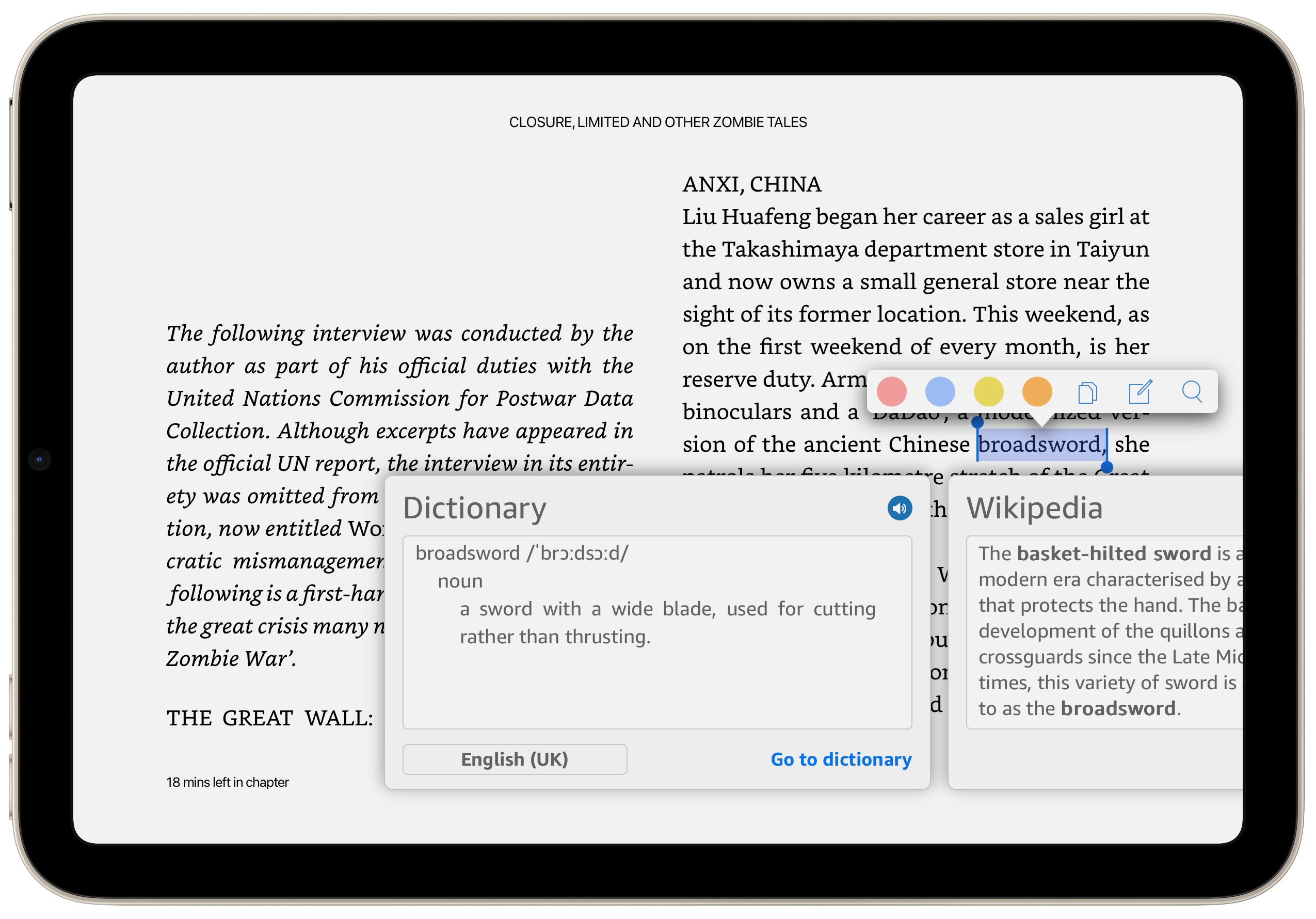
Il n’en va pas de même de l’application Antidote qui n’est pas qu’un simple dictionnaire.
La première fois que j’ai essayé Antidote, ce n’était d’ailleurs pas tant pour son dictionnaire (le Robert faisait et fait encore largement mon affaire) que pour son correcteur orthographique largement plus puissant que celui intégré au système. En raison des limitations du système de l’iPad, on ne bénéficie pas de certaines fonctions mais on les retrouvera sur la version web.
À ce propos, permettez-moi une petite digression. On dit souvent que les correcteurs orthographiques seraient responsables de la baisse du niveau des compétences d’écriture des élèves, que ceux-ci ne savent pas ou plus écrire, car le correcteur écrit pour eux. Laissez-moi vous compter une tout autre histoire. Quand j’ai acheté Antidote, ce n’était pas tant pour vérifier mon orthographe dont j’étais, en tant que prof de français, plutôt sûr, mais pour m’offrir le confort d’une relecture supplémentaire, une vérification certes, mais pas pour combler mes lacunes, mais plutôt pour m’assurer qu’une éventuelle étourderie n’aurait pas laissé traîner une disgracieuse et humiliante lacune. Or très vite j’ai pris conscience de la nécessité d’acquérir une nouvelle compétence que je n’avais pas et qui se trouvait être la maîtrise de la typographie. Antidote me conseillait en effet d’insérer ici des guillemets français, là un cadratin ou encore une espace (oui, on dit en principe UNE espace) insécable. J’ignorais tout cela et pendant quelque temps, Antidote a suppléé à mon ignorance et puis à force de lire et accepter ses recommandations, je les ai progressivement intégrées à ma pratique et faites miennes. En somme, j’ai appris. Le logiciel m’a servi de béquille, me disant quoi faire jusqu’à ce que je n’en aie plus besoin. Bref, le correcteur corrigeait pour moi, mais se faisant m’a instruit.
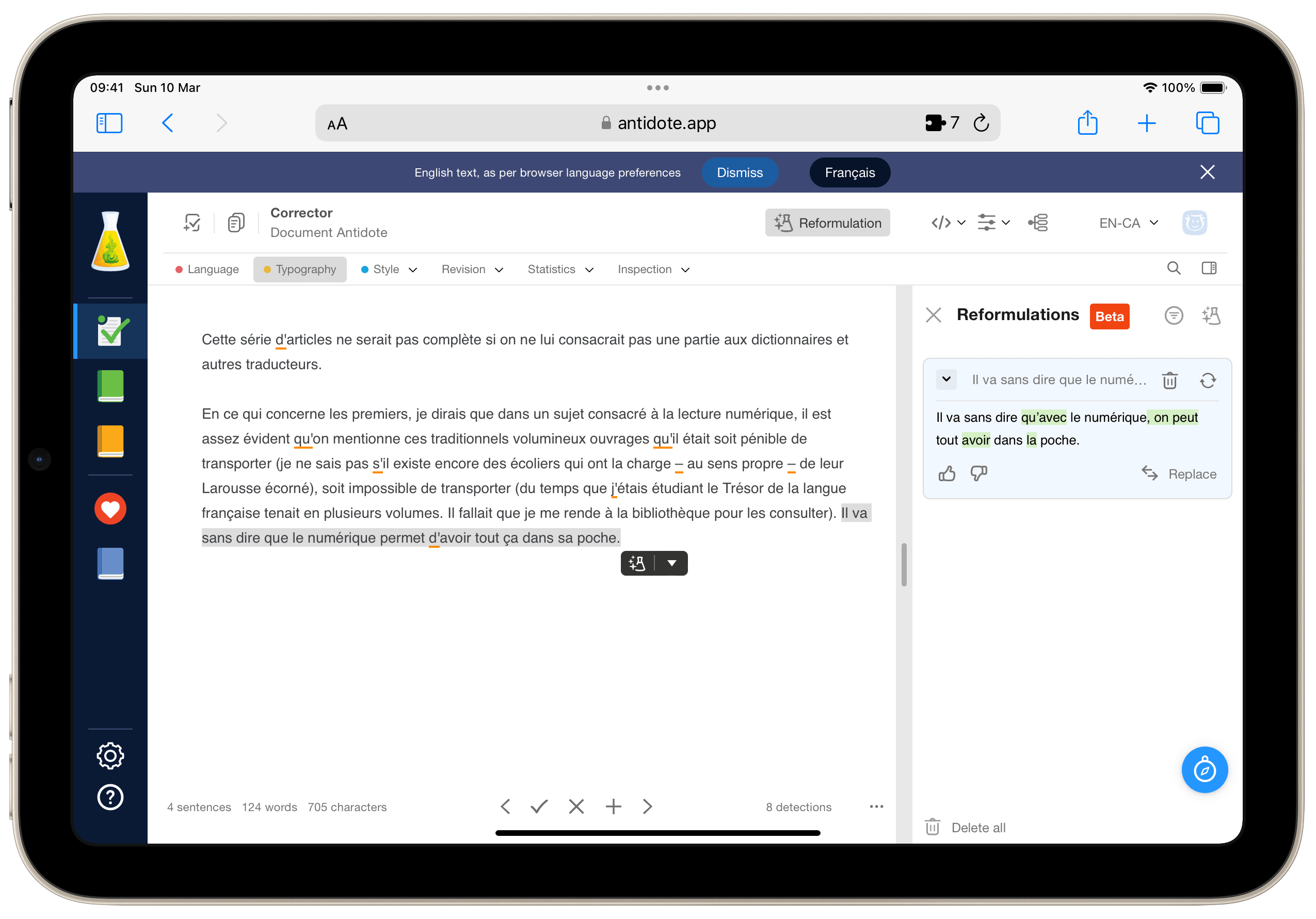
La correction porte donc aussi bien sur l’orthographe, la grammaire que la ponctuation et donc la typographie. Et forcément, on trouve à présent un peu d’intelligence artificielle vous proposant de donner une autre tournure à votre prose, mais c’est pour l’instant bien peu convaincant, et je n’en ai pas grande utilité. Pour l’instant en tout cas.
En fait, j’utilise aujourd’hui beaucoup Antidote pour son dictionnaire anglais. Il est en effet depuis quelques années bilingue. Je n’utilise que peu les autres fonctions. Elles sont pourtant, pour l’amoureux des mots, toutes très intéressantes. On a, par exemple, la possibilité de créer des favoris et parmi ces favoris, des listes que l’on pourra exporter dans un tableur (à partir de là les possibilités d’exploitation sont nombreuses. J’en ai parlé dans Utiliser Google Sheets pour apprendre du vocabulaire).
Il y a aussi des guides qui sont de vrais manuels de grammaire. Il y aussi des jeux qui vous permettent de sélectionner un mot au hasard et d’apprendre son étymologie ou l’équivalent du pendu.
Et aussi
On pourrait installer beaucoup d’autres dictionnaires, mais beaucoup de ceux que j’utilise sont en ligne. En voici une liste non exhaustive.
J’ai tout de même recours au TLFi (le Trésor de la Langue Française informatisé) du Centre National de Ressources Textuelles et Lexicales qui, avec le Petit Robert, est un… eh bien… un trésor, et pour lequel il existe une app offrant une interface plaisante, claire et aérée.
J’utilise aussi encore parfois le dictionnaire Larousse français anglais qui ne fait malheureusement pas l’objet d’autant d’attention de la part de son éditeur que le petit Robert. Il n’est plus mis à jour et l’interface n’est même plus adaptée au système d’exploitation actuel. C’est malheureusement le lot de nos vies numériques parsemées d’apps moribondes.
Il est quand même un autre Robert qui se partage mon cœur et qui est le Dictionnaire historique de la langue française. Quand je l’ai acheté, celui-ci avait la forme d’un livre dans l’application Books. Le dictionnaire est à présent une application autonome, certes un peu chère, mais deux fois moins que son équivalent papier, ce qui est suffisamment rare pour être noté. Et vous l’aurez compris, ce voyage dans dix siècles d’histoire des mots est bien plus léger et maniable et accessible.
Les traducteurs
Je ne vous ferai pas l’injure de vous présenter Google Translate ou DeepL. En revanche, je vous dirai quelques mots de ce que de telles applications changent à la lecture. Et pour ce faire, je remonterai à nouveau le temps pour évoquer mon passé de lecteur.
Pour tout dire, je ne crois pas avoir été jamais doué pour les langues. Je me souviens bien (au collège ou au lycée) avoir fait l’acquisition d’un dictionnaire anglais et d’ouvrages en édition bilingue (une page en anglais, l’autre, en regard, en français), mais peut-être n’étais-je alors pas prêt à fournir les efforts nécessaires, mais je me souviens bien de mon désarroi et surtout de mon impossibilité de progresser dans ma lecture et dans ma maîtrise de la langue anglaise. Je ne mentionnerai même pas la potentielle utilisation du dictionnaire (unilingue forcément) vous obligeant à quitter votre lecture pour ouvrir ledit dictionnaire. Autant dire que la plus grande flemme me paralysait. Le désarroi que j’éprouvais atteindrait le désespoir quand on nous demanda de lire Absalom, Absalom! de Faulkner, encore que la gageure m’avait valu un bruyant éclat de rire que je ravalais amèrement et silencieusement. Je savais que c’était perdu d’avance.
Tout allait changer avec la Kindle. Cet objet a été pour moi un vrai tremplin pour la maîtrise de la langue anglaise (work in progress here). Et c’est probablement une raison supplémentaire expliquant ma désaffection pour le livre papier qui avait échoué à m’aider, à me supporter (pour emprunter un anglicisme) dans mes efforts pour comprendre la langue de Shakespeare. De surcroit, coincidaient pour moi le besoin d’améliorer mon anglais et l’adoption naissante de la liseuse.
Or, sur un tel objet, non seulement le dictionnaire est à portée de doigt puisqu’il est intégré. Un appui prolongé sur le mot le fait apparaître. Mais si d’aventure, la définition ne vous aide pas à comprendre la phrase (et sincèrement cela m’arrive encore. J’ai cherché tous les mots, et le sens de la phrase continue de m’échapper), alors il vous reste la possibilité de traduire tout en restant dans le livre.
L’intégration de la traduction n’est pas l’apanage de la Kindle. On la retrouve dans tout l’OS de l’iPad. Ainsi quand vous lisez une page web, vous pouvez faire la même chose. Vous pouvez obtenir la traduction d’un mot.
Comme avec la Kindle, si le dictionnaire ne vous apporte pas l’aide désirée, vous pouvez obtenir la traduction d’une ou plusieurs phrases.
C’est également toute la page que vous pouvez faire traduire si vraiment la langue de Shakespeare (ou d’un autre) vous rebute. Remarquez que même le texte sur la photo est traduit !
Autant dire qu’avec de telles possibilités, on n’a aucune raison de ne pas lire ou de faire l’effort de lire dans une langue étrangère. On aura ainsi abandonné un effort (celui de chercher dans un dictionnaire) pour en fournir un autre (lire un texte dans une autre langue), et c’est souvent cela que permet la technologie : cesser de faire une chose, en somme perdre une compétence, pour en acquérir une autre ou en tout cas pour disposer d’un temps que l’on dévolue à d’autres tâches. L’exemple le plus criant est certainement Google Maps, mais je lui préfère celui de la machine à laver qui, en faisant le boulot pour vous, ne vous transforme pas en grosse feignasse méprisable, mais vous permet de faire autre chose. In fine, la machine à laver, c’est l’essor de la culture (c’est drôle, non ?).
Puis-je dire pour autant que je suis pleinement satisfait ? Que nenni. Pour que je le sois, il faudrait encore que les dictionnaires ou traducteurs soient mieux intégrés au système. Ils le sont déjà, mais ce sont ceux d’Apple qui le sont. Si vous voulez traduire une page, c’est le traducteur d’Apple que vous avez sous la main, mais si vous voulez DeepL, il vous faut quitter ce que vous étiez en train de faire et vous diriger d’un doigt alerte vers l’app idoine, ce qui est souvent la première étape d’un jeu pénible de va-et-vient.
Ce qu’il faudrait, c’est exactement ce qu’Apple a permis avec les claviers (souvenez-vous d’iOS 8). Depuis 2014 donc, vous pouvez télécharger des claviers comme vous le feriez avec des apps et les installer et ainsi les utiliser partout dans le système c’est-à-dire dans l’OS. C’est exactement ce qu’il faudrait pouvoir faire avec les dictionnaires ou traducteurs. Je voudrais, par exemple, convoquer Antidote directement dans l’application Kindle, pouvoir mettre un mot en favori et le retrouver et l’exporter dans des listes que je pourrais manipuler, éditer, exporter, enrichir, etc.
Bref, on commence à comprendre que le lecteur gâté l’est à double sens. Il est gâté comme on l’est quand on est comblé de cadeaux, mais il l’est aussi comme dans l’expression « pourri gâté ». On n’est jamais satisfait et c’est heureux puisque les appareils sur lesquels nous travaillons sont mis à jour à intervalles réguliers. Je ne suis pas bien certain que le souhait d’une telle intégration soit très partagé parmi les utilisateurs d’iOS, mais sait-on jamais.